Un modèle pour Syracuse
Réponses
-
PMF
Je te suis en mode silence radio, c'est quoi une matrice pour toi?Le 😄 Farceur -
Une matrice dans un tableur est une plage de données organisée en x lignes et y colonnes
Par rapport à une simple plage, les données sont liées entre elles par une relation.
On a va pouvoir définir dans chaque plage la position d'une donnée par rapport à sa ligne et sa colonne. On doit trouver entre la relation des positions et la relation algébrique des données une concordance.
Le plus souvent, une matrice se répète dans une dimension (vers le bas, vers la droite) voire 2 (vers le bas et la droite en même temps)
On va donc situer une donnée selon la position x et y + c le cycle (en une ou deux dimensions)
Quand on a compris les relations des données dans le cycle initial, et d'un cycle à l'autre, on a plus besoin de formules algébriques. On trouve la règle (souvent très simple) et on l'applique. C'est le propre des tableurs de compter comme ça (sommeprod et compagnie) -
Merci.
Silence radio mode: onLe 😄 Farceur -
@gerbrane
ouvre le micro quand ça te dit ! j'aime bien te lire.
Petit exemple pratique sur les matrices.
1) il est facile de voir les diagonales dans cette matrice de x. Ils se suivent en x + 1 comme par exemple en partant du 9 case rouge dans la colonne de gauche et en allant vers la droite en descendant
https://imagizer.imageshack.com/img922/6481/zJ0GbE.jpg
2) voici la règle du x pour toutes les diagonales
https://imagizer.imageshack.com/img922/4163/lrgU3X.jpg
Sinon le plus simple est de stocker les positions des 13 x dans le cycle 1 de la matrice
et d'ajouter +5 à chaque x à chaque changement de cycle
$\large \forall x \in \text{cycle, } x_{cycle} = x_{cycle-1} +5 $ -
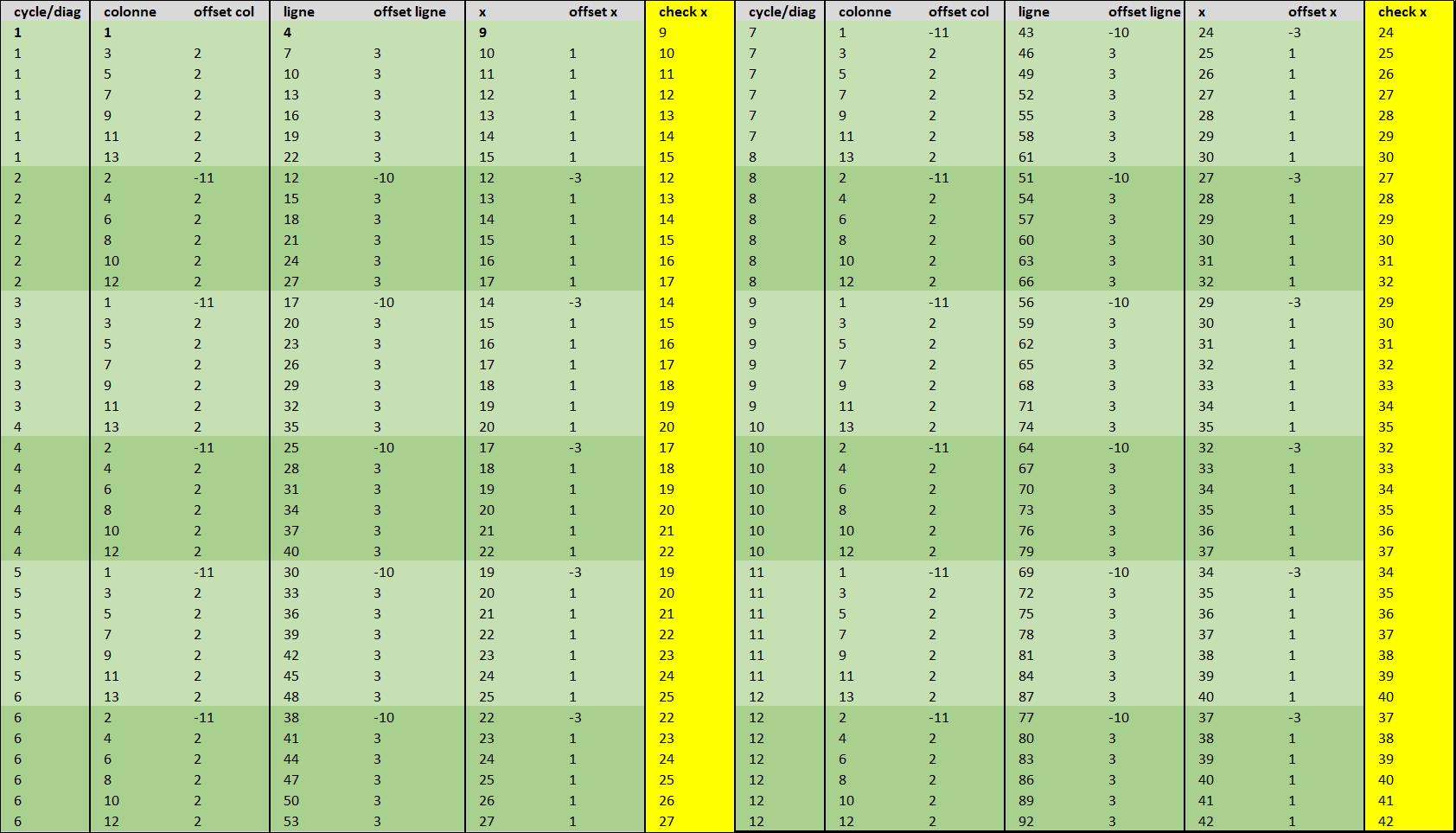
MODELE SYRACUSE, présentation et analyse des données dans le système matriciel du modèle
Je rappelle que nous analysons les données d'une suite d'entiers naturels k, ici de 28 à 170:
[size=small]28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170[/size]
qui s'associent aux clusters :
[size=small]7_24_5_35, 8_24_5_36, 8_25_5_37, 9_25_5_38, 9_26_5_39, 9_27_5_40, 10_27_5_41, 10_28_5_42, 10_29_5_43, 11_29_5_44, 11_30_5_45, 12_30_5_46, 12_31_5_47, 12_32_5_48, 13_32_5_49, 13_33_5_50, 14_33_5_51, 14_34_5_52, 14_35_5_53, 15_35_5_54, 15_36_5_55, 15_37_5_56, 16_37_5_57, 16_38_5_58, 17_38_5_59, 17_39_5_60, 17_40_5_61, 18_40_5_62, 18_41_5_63, 19_41_5_64, 19_42_5_65, 19_43_5_66, 20_43_5_67, 20_44_5_68, 20_45_5_69, 21_45_5_70, 21_46_5_71, 22_46_5_72, 22_47_5_73, 22_48_5_74, 23_48_5_75, 23_49_5_76, 24_49_5_77, 24_50_5_78, 24_51_5_79, 25_51_5_80, 25_52_5_81, 25_53_5_82, 26_53_5_83, 26_54_5_84, 27_54_5_85, 27_55_5_86, 27_56_5_87, 28_56_5_88, 28_57_5_89, 29_57_5_90, 29_58_5_91, 29_59_5_92, 30_59_5_93, 30_60_5_94, 30_61_5_95, 31_61_5_96, 31_62_5_97, 32_62_5_98, 32_63_5_99, 32_64_5_100, 33_64_5_101, 33_65_5_102, 34_65_5_103, 34_66_5_104, 34_67_5_105, 35_67_5_106, 35_68_5_107, 35_69_5_108, 36_69_5_109, 36_70_5_110, 37_70_5_111, 37_71_5_112, 37_72_5_113, 38_72_5_114, 38_73_5_115, 39_73_5_116, 39_74_5_117, 39_75_5_118, 40_75_5_119, 40_76_5_120, 40_77_5_121, 41_77_5_122, 41_78_5_123, 42_78_5_124, 42_79_5_125, 42_80_5_126, 43_80_5_127, 43_81_5_128, 44_81_5_129, 44_82_5_130, 44_83_5_131, 45_83_5_132, 45_84_5_133, 45_85_5_134, 46_85_5_135, 46_86_5_136, 47_86_5_137, 47_87_5_138, 47_88_5_139, 48_88_5_140, 48_89_5_141, 49_89_5_142, 49_90_5_143, 49_91_5_144, 50_91_5_145, 50_92_5_146, 50_93_5_147, 51_93_5_148, 51_94_5_149, 52_94_5_150, 52_95_5_151, 52_96_5_152, 53_96_5_153, 53_97_5_154, 54_97_5_155, 54_98_5_156, 54_99_5_157, 55_99_5_158, 55_100_5_159, 55_101_5_160, 56_101_5_161, 56_102_5_162, 57_102_5_163, 57_103_5_164, 57_104_5_165, 58_104_5_166, 58_105_5_167, 59_105_5_168, 59_106_5_169, 59_107_5_170, 60_107_5_171, 60_108_5_172, 60_109_5_173, 61_109_5_174, 61_110_5_175, 62_110_5_176, 62_111_5_177[/size]
et qui s'associent aux i'
[size=small]101717, 33621, 66901, 22293, 44373, 89173, 29525, 58709, 118101, 39125, 78165, 26053, 52053, 104213, 34645, 69397, 23093, 46165, 92373, 30773, 61525, 123093, 41013, 82005, 27333, 54669, 109333, 36437, 72885, 24277, 48581, 97109, 32341, 64725, 129365, 43093, 86229, 28725, 57429, 114901, 38285, 76565, 25521, 51043, 102085, 34029, 68053, 136113, 45365, 90709, 30229, 60469, 120917, 40305, 80597, 26865, 53717, 107461, 35797, 71621, 143189, 47701, 95445, 31797, 63573, 127189, 42381, 84757, 28253, 56501, 113009, 37667, 75333, 150669, 50221, 100445, 33481, 66961, 133923, 44641, 89281, 29769, 59521, 119041, 39691, 79361, 158721, 52907, 105815, 35271, 70543, 141085, 47047, 94057, 31385, 62729, 125409, 41819, 83615, 167211, 55743, 111483, 37167, 74335, 148649, 49563, 99099, 33059, 66075, 132151, 44077, 88157, 176159, 58769, 117439, 39179, 78311, 156585, 52207, 104415, 34825, 69609, 139219, 46433, 92867, 185625, 61911, 123821, 41273, 82547, 164999, 55031, 109999, 36687, 73343, 146665, 48895, 97791, 195553, 65193, 130387, 43479, 86957[/size]
Sachant que toutes ces valeurs ont les mêmes positions dans la matrice. Et que cette position est exprimée en Cycle_Colonne_Ligne dans une matrice dont chaque cycle de 13*13 cellules contient 13 variables.
Ces positions en Cycle_Colonne_Ligne sont :
[size=small]1_12_1, 1_4_2, 1_9_3, 1_1_4, 1_6_5, 1_11_6, 1_3_7, 1_8_8, 1_13_9, 1_5_10, 1_10_11, 1_2_12, 1_7_13, 2_12_1, 2_4_2, 2_9_3, 2_1_4, 2_6_5, 2_11_6, 2_3_7, 2_8_8, 2_13_9, 2_5_10, 2_10_11, 2_2_12, 2_7_13, 3_12_1, 3_4_2, 3_9_3, 3_1_4, 3_6_5, 3_11_6, 3_3_7, 3_8_8, 3_13_9, 3_5_10, 3_10_11, 3_2_12, 3_7_13, 4_12_1, 4_4_2, 4_9_3, 4_1_4, 4_6_5, 4_11_6, 4_3_7, 4_8_8, 4_13_9, 4_5_10, 4_10_11, 4_2_12, 4_7_13, 5_12_1, 5_4_2, 5_9_3, 5_1_4, 5_6_5, 5_11_6, 5_3_7, 5_8_8, 5_13_9, 5_5_10, 5_10_11, 5_2_12, 5_7_13, 6_12_1, 6_4_2, 6_9_3, 6_1_4, 6_6_5, 6_11_6, 6_3_7, 6_8_8, 6_13_9, 6_5_10, 6_10_11, 6_2_12, 6_7_13, 7_12_1, 7_4_2, 7_9_3, 7_1_4, 7_6_5, 7_11_6, 7_3_7, 7_8_8, 7_13_9, 7_5_10, 7_10_11, 7_2_12, 7_7_13, 8_12_1, 8_4_2, 8_9_3, 8_1_4, 8_6_5, 8_11_6, 8_3_7, 8_8_8, 8_13_9, 8_5_10, 8_10_11, 8_2_12, 8_7_13, 9_12_1, 9_4_2, 9_9_3, 9_1_4, 9_6_5, 9_11_6, 9_3_7, 9_8_8, 9_13_9, 9_5_10, 9_10_11, 9_2_12, 9_7_13, 10_12_1, 10_4_2, 10_9_3, 10_1_4, 10_6_5, 10_11_6, 10_3_7, 10_8_8, 10_13_9, 10_5_10, 10_10_11, 10_2_12, 10_7_13, 11_12_1, 11_4_2, 11_9_3, 11_1_4, 11_6_5, 11_11_6, 11_3_7, 11_8_8, 11_13_9, 11_5_10, 11_10_11, 11_2_12, 11_7_13[/size]
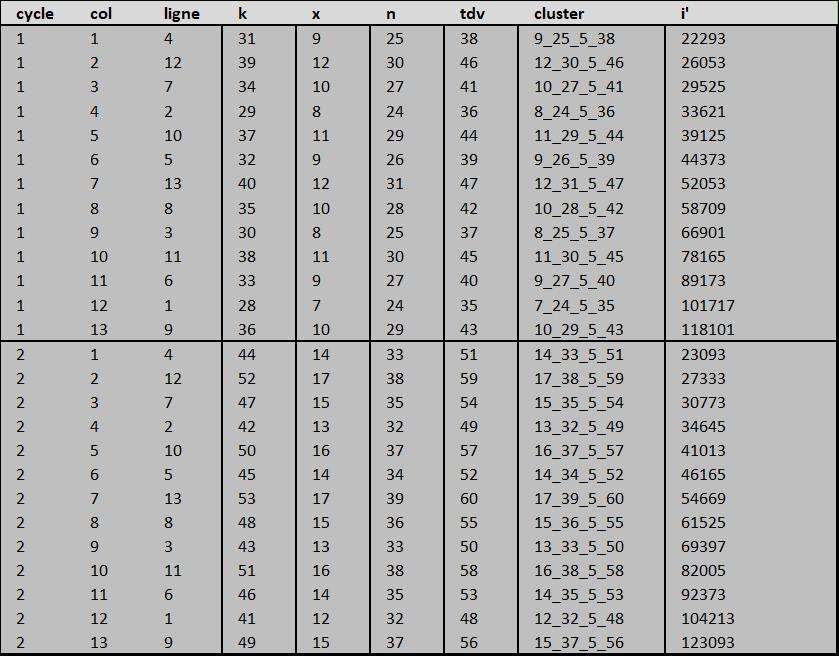
Voici la présentation des valeurs k, x, n, tdv et i' telles qu'on peut les trouver dans les cycles 1 et 2 de la matrice.
https://imagizer.imageshack.com/img924/1759/WqLo8x.jpg
De ces données, il est aisé de conclure que
$\large \forall k \in \text{matrice, } k_{cycle} = k_{cycle-1} +13$
$\large \forall x \in \text{matrice, } x_{cycle} = x_{cycle-1} +5$
$\large \forall n \in \text{matrice, } n_{cycle} = n_{cycle-1} +8$
$\large \forall tdv \in \text{matrice, } tdv_{cycle} = tdv_{cycle-1} +13$
https://imagizer.imageshack.com/img924/4108/IkHHlj.jpg
La médaille Fields en chocolat de la semaine est offerte à celui ou celle qui sera capable de trouver la fonction de i'
entre k et i'
k : 28, 41, 54, 67, 80, 93, 106, 119, 132, 145, 158
i' : 101717, 104213, 109333, 114901, 120917, 127189, 133923, 141085, 148649, 156585, 164999
l'approximation étant un polynôme de degré 3
$i' \approx -0,0058*k^{3} + 3,0263*k^{2} + 99,571*k + 96198 $ -
Bonjour
j'obtiens encore une fois un polynôme de degré 10
63745960181071624/2360961488187671x^10+6839420416752776000/1683001154901051x^9-41766405129083945000/1724721273894779x^8+22/2764715496990945x^7+24/7906404819904753x^6+24/4739747395408795x^5+24/5859315304620103x^4-946769850640682000/6497864476226843x^3-731810299176076400000/3336838525812277x^2+21/6674355688060191x+22/4657150717290885
BERKOUK -
J'envoie une bouteille à la mer...
Si du bord de votre yacht vous la voyez passer, merci de lire le message et de voir ce que vous pouvez faire.
Message :
J'explore les capacités prédictives de mon modèle Syracuse qui peut générer une infinité de clusters x_n_i_tdv en fonction de certains paramètres initiaux.
Ces paramètres sont
valeur de $\lambda = 7 \Rightarrow tdv = k + \lambda $
valeur de $i = 5$
Et les règles pour passer d'un cycle au suivant sont :
valeur de $k_{0} = 31 \Rightarrow k_{1} = k_{0} +13 = 44 $
valeur de $x_{0} = 9 \Rightarrow x_{1} = x_{0} +5 = 14 $ (nbr étapes impaires)
valeur de $n_{0} = 25 \Rightarrow n_{1} = n_{0} +8 = 33 $ (nbr étapes paires)
Valeur de $tdv_{0} = 38 \Rightarrow tdv_{1} = tdv_{0} +13 = 51 $
Le premier cluster 9_25_5_38 associé à k=31 est donc suivi du deuxième cluster 14_33_5_51 associé à k=44
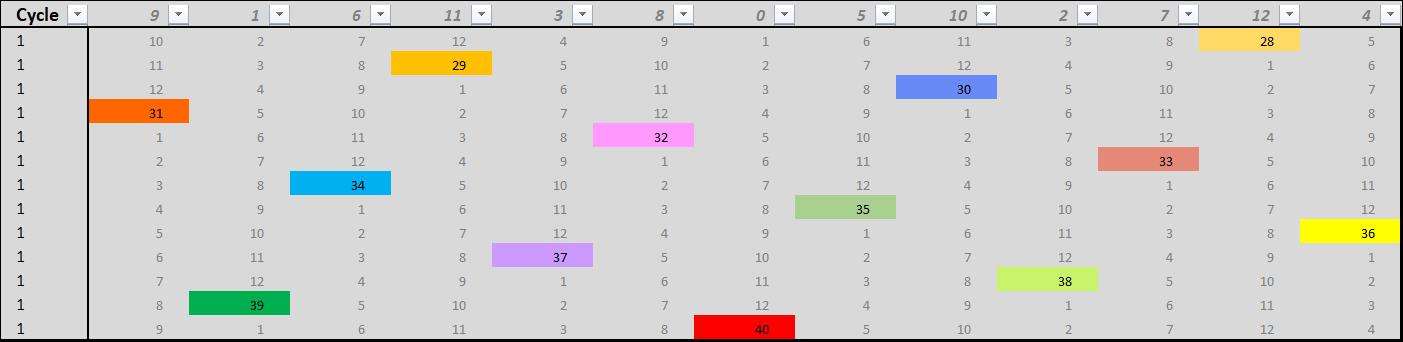
Le modèle utilise un système matriciel basé sur une matrice de base de 13*13 cellules dans lesquelles sont positionnées 13 valeurs
qui sont au choix celles de x, n ou tdv. On passe d'un cycle à un autre en appliquant les règles indiquées ci-dessus
Quand k fait des sauts de 13 cela veut dire que je ne prends qu'un seul k par cycle
Danc ce cas, k = 31 est situé en colonne 1 et ligne 4 du cycle 1
https://imagizer.imageshack.com/img922/8519/nQwGhX.jpg
L'immense intérêt du modèle est d'être totalement indépendant des suites de Collatz pour faire des prédictions.
Il suffit de faire des additions. Plus simple, c'est pas possible.
Je me suis donc amusé à répéter le cycle 1000 fois pour arriver au cluster :
5004_8017_5_13025 associé au k = 13018
On parle donc d'un entier impair (un i') dont le tdv est de 13025. Sympa le nombre...
Je ne vous demande pas de le calculer. Enfin si vous voulez faites-le ! Mais je me moque de ce k au tdv 13025. Ce que je voudrais c'est la règle qui permet de passer d'un i' à l'autre de cycle en cycle. Donc entre deux mojitos et un tour en jet-ski, si vous avez deux ou trois neurones de libre ... quelle serait au moins votre idée pour trouver ce i' sachant que nous avons son identité complète de cluster.
Le pdf joint donne les prédictions jusqu'à x = 1004
Bonne vacances ! -
Hello Berkouk
Merci de ton aide.
Le souci des polynômes et autres splines est de faire du ''curve matching'' au cas par cas.
On va toujours trouver une courbe qui passe par les points mais la formule en elle-même ne contient pas d'information.
Je pense qu'il faudrait reprendre ce qui s'est dit sur ces 2 fils depuis le début. Il y a peut-être quelque chose qui m'a échappé.
le problème est qu'il y a pas mal de formules mais aucune ne donne i' même si l'on connait x, n , i et le tdv.
mon modèle trouvera je pense d'ic quelques jours tous les x_n_i_tdv quelque soit i et la valeur de la suite k et de $\lambda$ mais les i' semblent être dans une autre dimension. Ils ne sautent pas d'un cycle à l'autre avec la même valeur. Actuellement je ne les trouve qu'avec la bdd en croisant avec le x_n_i_tdv. La seule chose que je sais est que ces i' sont les premiers du cluster défini par le modèle. -
https://imagizer.imageshack.com/img922/9127/S7xRqX.jpg
[size=small]art mathématique
données des suites de Collatz, logiciel microsoft excel, affichage nuage de points[/size] -
PMF a écrit:La médaille Fields est offerte ...
k : 28, 41, 54, 67, 80, 93, 106, 119, 132, 145, 158
i' : 101717, 104213, 109333, 114901, 120917, 127189, 133923, 141085, 148649, 156585, 164999
Tu as proposé un polynome de degré 3. Soit, mais pourquoi proposer un polynome ?
Est-ce que tu connais un autre type de fonction que les fonctions polynomes ? Un type de fonction dont on a parlé à différentes reprises dans cette discussion ... Un type de fonction avec le même ADN que les suites de Collatz ?
Indice n°1 : 141085/133923= ... , 148649/141085= ... , 156585/148649= ...
Indice n°2 : $2^8/3^5= $ ...
Je crois que je t'avais suggéré déjà de regarder les derniers de cordée, plutôt que les premiers de cordée (c'est une des expressions qu'on utilisait à l'époque pour parler de ces nombres). Et l'idée était que l'analyse des derniers de cordées serait plus facile, la formule pour donner les derniers de cordées serait plus facile à trouver.
J'ai fait quelques vérifications, et effectivement, les effets 'aléatoires' de la suite de Collatz impactent les premiers de cordée, mais impactent très peu les derniers de cordée.
Par exemple pour le cluster 14_33_5_51, cette formule très simple donne un 'dernier de cordée' à 8979, et la vraie valeur est à 8969. Cette formule très simple donne un nombre un peu plus grand que la vraie valeur, et c'est systématique ; on sait que la vraie valeur sera toujours un peu plus petite que le résultat de cette formule.
Pour les premiers de cordées, les effets 'aléatoires' sont plus importants. Il y a des formules possibles, simples, mais avec une marge d'erreur beaucoup plus importante.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
Lourran a écrit:Un type de fonction avec le même ADN que les suites de Collatz ?
Voilà le retour du Lourran que j'aime bien. :-)
Mais oui bien sûr ! J'ai répond ce matin à Berkouk que les polynômes et autres splines rejoignent les points mais ne contiennent pas d'information, hormis de confirmer numériquement ce que l’œil voit naturellement. http://www.les-mathematiques.net/phorum/read.php?43,2058452,2064116#msg-2064116
Ceci dit depuis hier je me bats avec effectivement les minorants ou majorants pour chasser le i'
par exemple avec des fonctions Excel comme
IMPAIR(2^(tdv-x-1)/3^x)
IMPAIR(2^(tdv-x)/3^x)
et oui les majorants sont plus proches des i'
A part ça je me suis replongé dans cette égalité :
3^x/(2^(x*LOG(3;2)+LOG(i';2)))*i' = 1
Dont il est possible de sortir
$\Delta$ =x*LOG(3;2)+LOG(i';2)
partie sans i' : $\Delta$' = x*LOG(3;2)
partie avec i' : $\Delta$'' = LOG(i';2)
$\Delta$' / $\Delta$'' : x*LOG(3;2)/LOG(i';2)
Comme mon modèle a la gentillesse de me sortir la valeur de x, j'ai la valeur de la partie "sans i''
ce qui veut dire que dans l'égalité à part le rouge tout est connu
Ce ratio évolue suivant une fonction de i'
par exemple
Pour tous les clusters ayant en commun x =100
i'
[size=small]19593; 19883; 39009; 39015; 39187; 39707; 39767; 40105; 76223; 76231; 78017; 78019; 78031; 78111; 78119; 78267; 78373; 78375; 78761; 79263; 79415; 79533; 79551; 80209; 80211; 80697; 80809; 81007; 150249; 150255; 152063; 152447; 152463; 153447; 153673; 153691; 154395; 156027; 156033; 156035; 156037; 156039; 156061; 156207; 156223; 156239; 156315; 156443; 156535; 156749; 156751; 156753; 156799; 157353; 157497; 157523; 157543; 158527; 158601; 158829; 159069; 159081; 159099; 159103; 159791; 159851; 160419; 160421; 160425; 160859; 161383; 161395; 161535; 161545; 161619; 161913; 161929; 162015; 167015[/size]
ratio
[size=small]11,11626361; 11,09976183; 10,39216133; 10,39201014; 10,38768784; 10,37475637; 10,37327724; 10,36499409; 9,772897303; 9,772806064; 9,752714597; 9,752692402; 9,752559251; 9,75167219; 9,751583543; 9,749945494; 9,748774536; 9,748752461; 9,744504243; 9,739015884; 9,737362137; 9,736080875; 9,735885625; 9,728783638; 9,728762156; 9,723560659; 9,722367186; 9,720262054; 9,216508007; 9,216477131; 9,207238248; 9,205292519; 9,205211571; 9,200252253; 9,199118465; 9,199028247; 9,195509364; 9,187423495; 9,18739395; 9,187384102; 9,187374254; 9,187364406; 9,18725609; 9,18653772; 9,186459042; 9,186380373; 9,186006826; 9,185378173; 9,1849267; 9,18387773; 9,183867935; 9,183858139; 9,183632885; 9,18092608; 9,180224327; 9,180097701; 9,180000314; 9,175226579; 9,174868978; 9,173768402; 9,17261189; 9,172554118; 9,17246747; 9,172448216; 9,169144958; 9,168857671; 9,166144232; 9,166134698; 9,166115629; 9,164049967; 9,161564591; 9,161507784; 9,160845403; 9,160798116; 9,160448296; 9,159060316; 9,158984864; 9,158579458; 9,135431608[/size]
J'en suis là. Si tu vois quelque chose, welcome ! -
J'ai fait une expérience.
J'avais en tête une formule qui donnerait le cluster à partir d'une valeur quelconque de i'.
Plus précisément, une formule qui donnerait 4 ou 5 clusters possibles, en disant : c'est quasi-sûr que que le cluster de i' est l'un de ces 5 là.
A l'arrivée, ça marche beaucoup moins bien que ce que j'imaginais.
Pour un nombre i' de l'ordre de 1 ou 2 millions, je sais déterminer par exemple 10 clusters, et je sais hiérarchiser ces 10 clusters.
Dans 7% des cas , le cluster que je donne en n°1 est correct. Dans 6% des cas , le cluster correct est celui qui ressortait comme 2ème choix ... etc etc
Avec 10 clusters, j'ai la bonne réponse dans quasiment 50% des cas. Seulement 50% des cas.
Petit point de repère :
J'ai déterminé les chemins de Syracuse pour tous les nombres entre 1 900 000 et 2 100 000. Il y a 124 clusters sur cet intervalle.
Et si je prends les clusters pour lesquels le minorant est inférieur à 2000000, et le majorant est supérieur à 2000000, il y en a 45.
En d'autres mots, sur une zone assez compacte (1% d'amplitude par exemple), on a environ 45 clusters qui se chevauchent.
Et si on étudie les nombres aux alentours de 20 000 000 au lieu de 2 000 000... c'est pire, bien entendu.
Précision : je parle ici de cluster au sens x_tdv (nb étapes impaires, et nb étapes totales), pas au sens x_n_i_tdv.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
Hello Lourran
Chaque essai est toujours révélateur de quelque chose. On a une intuition. Le résultat révèle souvent que l'intuition n'est pas la bonne, mais il ouvre une petite porte. Je suis donc curieux de voir tes données. Peux-tu mettre un fichier à disposition ?
De mon côté j'avance sur mon modèle en essayant de trouver ce satané i' mais en "brut force" : le résultat exact ou la mort !
Il faudrait en fait que je sois bcp plus fort avec les suites que je ne le suis, ça irait surement plus vite, mais j'a trouvé des trucs.
D'abord le système de matrices est hyper costaud et fiable, et si les règles sont bonnes, elles le seront à l'infini.
Toutes les suites que l'on associe à k sont faites avec de vulgaires additions : x, n et tdv. Aucun problème de précision (normalement)
Le souci est que le i' ne saute pas droit contrairement aux 3 autres. Pour contourner le problème, je cherche $\Delta = log_2{i'}$
Cette valeur ne saute pas droit mais c'est déjà plus linéaire que i'.
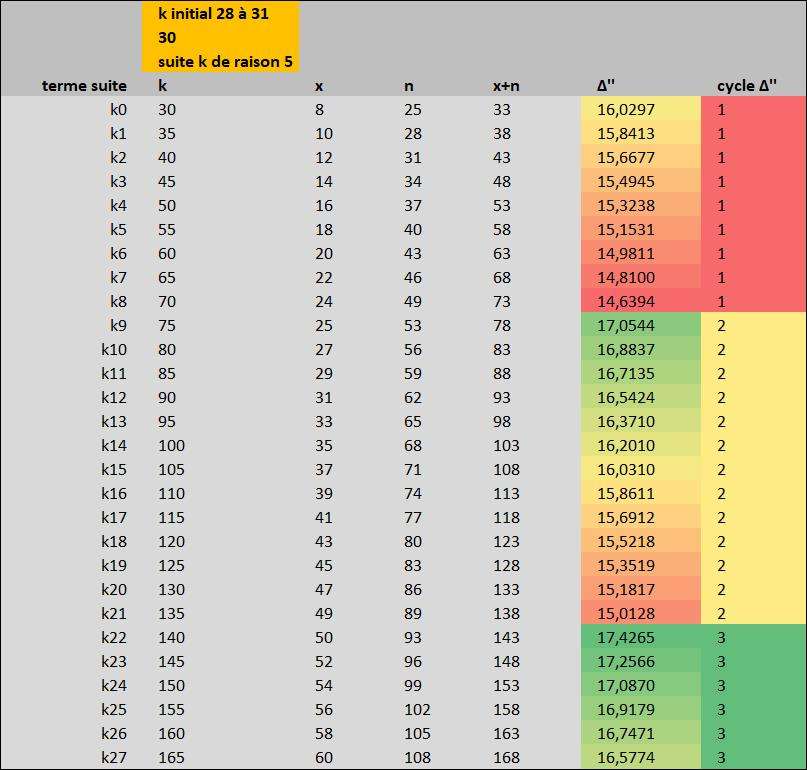
J'ai compris comment ça marche sur un petit groupe de suites k
1) l'expérience concerne k entre 28 et 170
2) on peut découper cette suite en 5 suites de raison 5 partant de k =28, 29, 30, 31, 32
3) Pour chacune de ces suites, on remarquera encore 3 suites qui correspondent à des alignements de $\Delta$ :
k : 28, 33, 38, 43, 48, 53, 58, 63, 68, 73, 78, 83,
$\Delta$ : 16,63420129; 16,44431933; 16,25423514; 16,08258568; 15,90888513; 15,73843537; 15,56810457; 15,39516592; 15,22449164; 15,05447714; 14,88364563; 14,71344022;
k : 88, 93, 98, 103, 108, 113, 118, 123, 128, 133, 138, 143, 148,
$\Delta$ : 17,12756114; 16,95661438; 16,78607815; 16,61604623; 16,44606557; 16,27614258; 16,10621531; 15,93684494; 15,76650303; 15,59697589; 15,42773841; 15,25779295; 15,08783573;
k : 153, 158, 163... (qui est certainement aussi de 12 termes)
$\Delta$ : 17,5020315; 17,33209776; 17,1621651
Du coup avec les coefficients de régression linéaire on trouve la pente et l'ordonnée origine qui généreront les $\Delta$ futurs
Les pdf joints sont les données de cette partie du modèle.
Il va falloir que je continue encore un peu ma mise en place pour voir si les prédictions sont bonnes, mais j'ai assez confiance que ce modèle soit "présentable" courant aout.
NOTE ; je viens de rajouter un pdf -
On peut bien comprendre le processus avec ce visuel
https://imagizer.imageshack.com/img923/959/cNiwnm.jpg
la suite k de raison 5 va de 30 à 165
la suite x de raison 2 va de 8 à 60
la suite n de raison 3 va de 25 à 108
ce qui crée aussi une suite x+n
la suite x+n de raison raison 5 va de 33 à 168
On voit $\Delta$ se "réinitie" 3 fois dans ce tableau
Mais ce n'est pas grave car cela se détecte par la méthode des sauts.
Si un $\Delta$ est plus grand que son prédécesseur il y un saut
A partir de ce tableau, j'ai une fonctionnalité du modèle qui repère ces sauts (position & hauteur) et calcule les coef de régression
https://imagizer.imageshack.com/img924/6564/zBAuAQ.jpg
Donc si je fait un stockage de ces règles de suites k, x, n, x+n et $\Delta$
pour des départs k 28, 29, 30, 31, 32
Je peux aller "en théorie" aussi loin que je veux,
Donc le temps de finir la mise en place et je commence les vérifs ! -
Voici une suite incroyable, mais qui hélas ne dure pas très longtemps.
Très simplement, il s'agit d'un classement de i' dans l'ordre des x puis des n, ne concernant que le i = 5
Nous avons 8 i' avec x = 2 pour n : 1, 3, 5, 7, 9, 11, 13, 15
et
14 i' avec x = 3 pour n : 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18
La séquence i' étant :
pour x = 2 : 3, 13, 53, 213, 853, 3413, 13653, 54613,
pour x = 3 : 17, 35, 69, 141, 277, 565, 1109, 2261, 4437, 9045, 17749, 36181, 70997, 144725
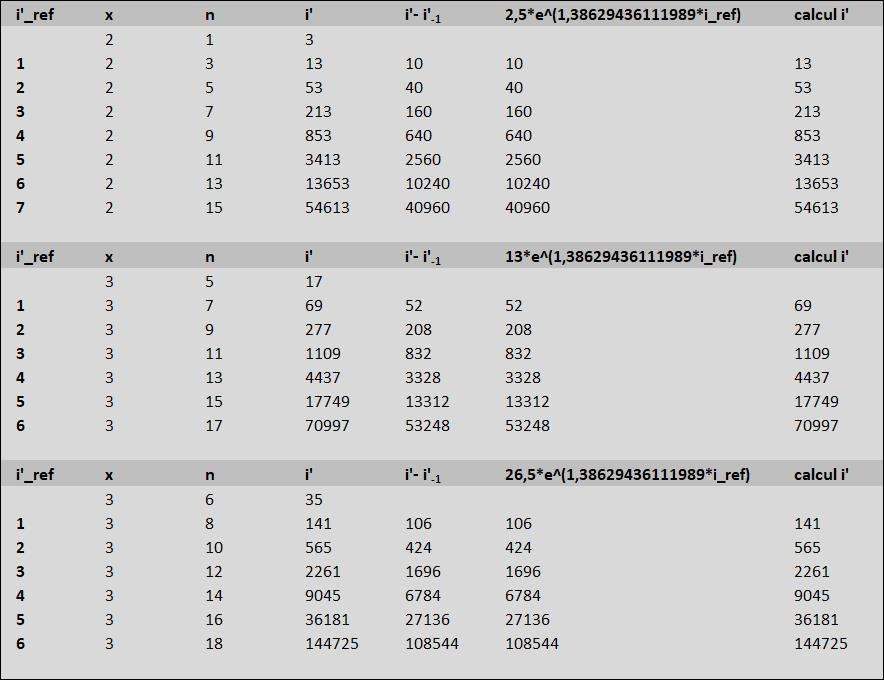
La beauté de la chose réside dans la manière d'écrire la différence de chaque i' avec son prédécesseur :
pour x = 2; $ \large i'- i'_{-1} = 2^{n} + 2^{n_{-1}}$
13-3=2^3+2^1
53-13=2^5+2^3
213-53=2^7+2^5
853-213=2^9+2^7
3413-853=2^11+2^9
13653-3413=2^13+2^11
54613-13653=2^15+2^13
pour x = 3 ; $\large i'- i'_{-1} = 2^{n-2} + 2^{n-n_{0}}$
35-17=2^4+2^1
69-35=2^5+2^1
141-69=2^6+2^3
277-141=2^7+2^3
565-277=2^8+2^5
1109-565=2^9+2^5
2261-1109=2^10+2^7
4437-2261=2^11+2^7
9045-4437=2^12+2^9
17749-9045=2^13+2^9
36181-17749=2^14+2^11
70997-36181=2^15+2^11
144725-70997=2^16+2^13
Bon faut pas rêver, ça va pas plus loin.... mais quel feu d'artifice !
Après un truc comme ça on se dit qu'il y a peut-être un peu de cette structure dans d'autres différences mais j'ai encore pas trouvé le truc ! -
Doesn't such a wonderful sequence ring a bell for any of you?
Je le dis en anglais parce que vous êtes peut-être en vacances à l'étranger B-)
Plus sérieusement, ça ne dit vraiment rien à personne que :
la différence de deux i' successifs puissent être la somme de deux puissances de 2,
ces exposants étant en relation avec n, le nombre d'étapes paires,
et l'ordre de ces i' étant celui des x, le nombre d'étapes impaires et des n ?
hum ? -
La première relation est plus simple que ce que tu dis.
Cette relation est : $ i'_{n+1} = 4 i'_n $
C'est la même relation que l'on a avec les 'souches' : 5 21 85 341 etc etc
u = 5 (respectivement 21 85 etc)
Pour passer de cette série (les souches 5 21 85 ...) à ta série ( 3, 13 , 53) , on ne fait que l'opération y=(2x-1)/3 (= une montée et une descente de Syracuse)
Donc la relation $ i'_{n+1} = 4 i'_n $ reste d'actualité.
Et pour les souches, la propriété $ souche_{n+1} = 4*souche_n+1$ s'explique très facilement aussi.
Et à partir de la relation $ i'_{n+1} = 4 i'_n $ , la relation que tu as est une conséquence directe. Si tu prends un nombre quelconque (entier ou pas, et que tu fais 4x+1 à chaque étape, les différences successives seront en progression géométrique de raison 4.
Tu dis que cette propriété n'est valable que pour les premières valeurs. Ca doit être du à un choix bizarre dans tes conventions.
Pour ta 2ème série, tu as en fait 2 séries enchevétrées :
17 69 277 1109 etc
et 35 141 565 2261 9045
Et dans chaque série, on a la relation : $ y_{n+1} = 4y_n+1 $
Toujours cette même série.
Pareil. Ces 2 séries n'ont pas de raison de s'arrêter.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
bravo et merci, merci, merci, merci, merci !
le choix et le classement des i' dans la bdd est crucial:
- élimination des i <> 5
- élimination des rank de clusters <>1 (on ne garde que les premiers ou minorants de cluster)
- classement dans ordre croissant des x puis l'ordre croissant des n
Je viens de passer un bon moment à réfléchir sur ces suites en suivant tes explications et j'arrive au tableau suivant
(oui je sais j'ai encore fait un tableau...)
https://imagizer.imageshack.com/img922/6906/1F0puE.jpg
j'ai donc traité 3 suites partant de 3, de 17 et de 35
et en cherchant un peu j'ai trouvé la formule qui unifie tout ça.
En effet chacun des i' de chacun des groupes se calcule strictement de la même façon :
1) trouver le $i'_{0}$ de la suite : c'est le i' qui a le plus petit n d'une série de même x (+ les conditions générales)
2) nommer i'_ref la numérotation de la suite, le successeur de i'0 ayant un $i'_{ref}=1$
3) calculer la différence entre i' et son prédécesseur tel que
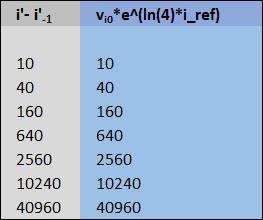
$\Large i' - i'_{-1} = v_{i_{0}}* e^{1,38629436111989*i'_{ref-1}}$
$\large v_{i_{0}}$ étant la variable spécifique à cette suite
4) additionner pour chaque ligne $i_{0} + \Sigma (i' - i'_{-1}) $
5 )Je remarque la formule des différences i' utilise 1,38629436111989
qui est cité ici https://fr.wikipedia.org/wiki/Epsilon_algorithme
dans un article nommé Epsilon algorithme
la valeur étant dans le tableau : ''Tableau des différences divisées pour l'interpolation polynomiale de ln(x) en 3 points''
Moi je suis arrivé à cette valeur parce que c'est le coefficient de régression d'une courbe de tendance exponentielle entre les différences
$i' - i'_{-1}$ et les $i'_{ref}$. Pour les 3 séries, j'ai toujours cette valeur.
Evidemment il serait intéressant de comprendre le pourquoi et le comment du rôle de cette variable. Que pourrais-tu nous en dire ?
De mon côté je vais évidemment trouver une solution pour sortir "en masse" les $\large v_{i_{0}}$ de chaque série (j'ai déjà fait ce genre de manips - ça va aller vite)
j'ai le feeling d'être très près de la finalisation du modèle ! En effet jamais je n'ai eu une telle filante pour désigner un i' depuis les données structurelles (x, n...)
J'ai nommé la fonctionnalité ''Group of Differences' soit GOD. C'est totalement lamentable mais au vu du fil de l'été du shtam http://www.les-mathematiques.net/phorum/read.php?43,2062264
cela me semblait inévitable -
Ohhh , ça pique les yeux ! $ e^{1.38624 *i_{ref}} $
Pourquoi pas $4^{i_{ref}}$ , tout simplement ?
Et le 1.38624 .. qui te chagrine, tu vas le trouver aussi si tu tapes "=ln(4)" dans Excel.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
ok je m'attendais à mieux :-(
tu as tout de même regardé le lien ?
https://fr.wikipedia.org/wiki/Epsilon_algorithme
de toute façon cela simplifie la formule et moi je fais un modèle. -
Voilà donc la formule GOD corrigée
$\Large i' - i'_{-1} = v_{i_{0}}* e^{ln(4)*i'_{ref-1}}$
et les données -
Ce lien parle de méthodes de calcul numérique ... certainement intéressant, mais aucun intérêt dans ton cas.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin
-
$e^{ln(4) * X} $... ok si on veut.
Mais ça s'écrit aussi $4^X $ Et donc dans ton cas $4 ^{ i'_{ref-1} } $ mais je pense que c'est plutôt $4 ^{ i'_{ref}-1 } $ ?
Dans excel : power(4 ; X) ou exp ( ln(4)*X ) ... ces 2 formules sont strictement équivalentes.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
Voilà donc une étape importante dans la conception de ce modèle. La version précédente pouvait prédire des clusters.Mais c'est la première fois qu'il peut grouper la prédiction de clusters et d'y associer un i'.
Il faut savoir que cette version du modèle est préréglée sur les i = 5 et ne cherche que les i' minorants de clusters.
Son premier module analyse la bdd et le deuxième prédit de nouvelles suites de Syracuse qui sont hors de cette bdd.
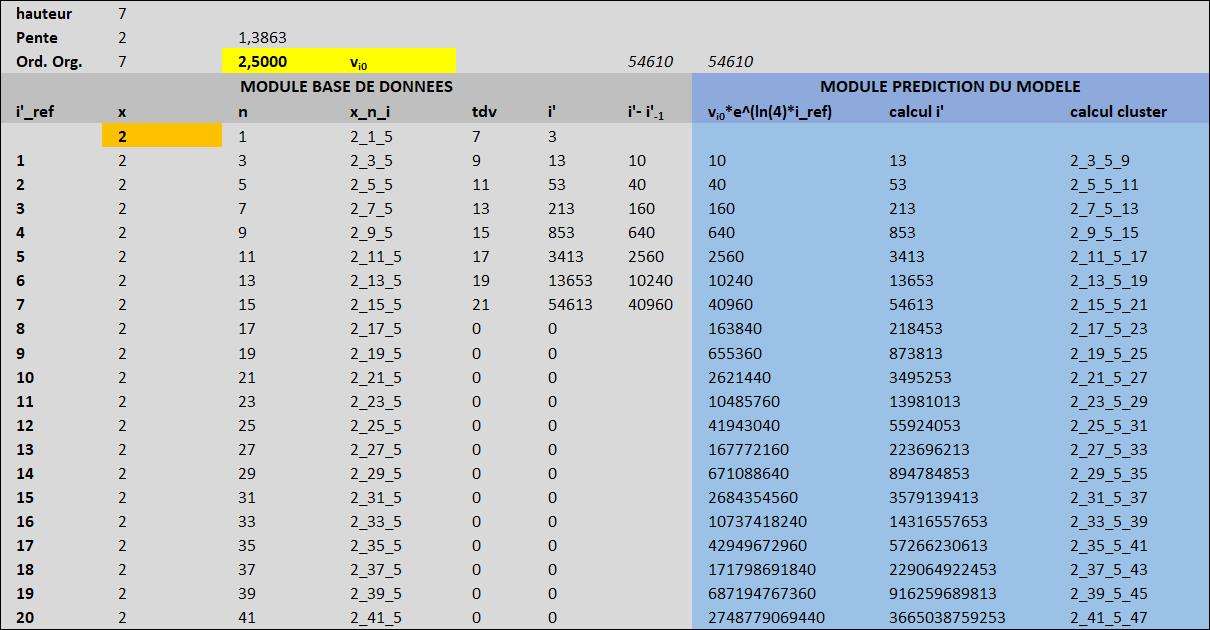
MODULE 1 ANALYSE DE LA BDD
(Cellules en gris)
On commence en choisissant un x, ici c'est 2
Une recherche est faite dans la bdd pour trouver le plus petit n associé au x : le modèle trouve n = 1
La suite de n pour les 20 lignes suivantes sera de raison 2 (c'est aussi un préréglage)
La recherche dans la bdd trouve 8 tdv et 8 i'
On peut donc calculer 7 différences de i' successeur - prédécesseur
Sur les données tdv on calcule les coefficients de régression linéaire
en haut à droite du tableur Pente = 2 et Ord. Org. = 7
Sur les données $i' - i'_{-1}$ on calcule les coefficients de régression exponentielle
en haut à droite du tableur Pente = 1,3863 = ln(4) et Ord. Org. = 2.5
Ce qui suffit pour alimenter le module 2
MODULE 2 PREDICTION DES CLUSTERS ET DES I'
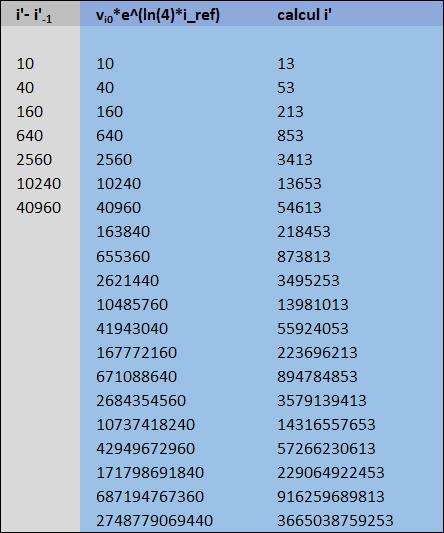
De manière à vérifier la validité des coefficients, le calcul des différences est repris à partir de i'_ref = 1
Ce qui permet de valider que pour les 7 premières le calcul de la formule est correct
$\Large i' - i'_{-1} = v_{i_{0}}* e^{ln(4)*i'_{ref-1}}$
Le $v_{i_{0}}$ est la valeur Ord. Org. = 2.5
Pour le calcul de la prédiction du i', il suffit d'additionner le $i'_{0}$ à la somme cumulée des différences
=F6+SOMME(H7:H7) ou F6 est $i'_{0}$
la ligne suivante est =F6+SOMME(H7:H8).....
Quant au cluster on calcule pour la ligne du i'_ref = 1
D7&"_"&B2*A7+B3 où D7 est le x_n_i, B2 la pente = 2, A7 le i'_ref et B3 l'Ord. Org. = 7
On peut en théorie prolonger ce calcul à l'infini, mais en pratique dans Excel on peut pas dépasser 10^15
Ce qui me fait évidemment le plus plaisir c'est de vérifier que ça marche
exemple i'_ref 20
i' = 3665038759253 pour le cluster 2_41_5_47
un petit tour sur le site de Raoul
https://repl.it/repls/TenderGuiltyFolders#main.py
et on entre le i' dans la ligne 25 Iprime
et on clique sur la petite flèche et.....
x_n_i_tdv : 2_41_5_47
Là je dois avouer qu'après 7 mois de boulot, ça fait plaisir, ouf !!!
Les questions que je vous pose à présent sont très simples, mais je voudrais que vous y répondiez en toute franchise.
1) Le modèle, même en ne se basant que ce premier x, et qui est de plus limité aux i = 5 et aux minorants de clusters, fait-il oui ou non une véritable prédiction d'un cluster et de son i' des lignes i'_ref 8 à 20, et ses résultats sont-ils justes ?
2) Connaissez-vous une autre méthode pour prédire les i' et clusters des lignes i'_ref 8 à 20.
3 ) Je rappelle ici qu'en portant ces formules sur python il n' y aurait pas de limite de calcul. Donc connaissez-vous une autre formule qui aurait la même capacité.
4) Je vais évidemment continuer avec les autres x. Qu'attendez-vous de ces futurs résultats pour juger ce modèle ?
Techniquement je suis assez confiant pour la suite. J'ai l'avantage d'avoir avec le système des matrices un autre moyen de prédire les clusters. Donc je devrais à un moment donné croiser les informations des deux méthodes de ce modèle. -
On a donc une suite géométrique, de raison 4.
Par quel miracle ?
Bon, ça n'a rien de miraculeux.
Le chemin de Syracuse de i' jusqu'à 1, il finit forcément par 16 8 4 2 1.
On a une autoroute : $1 2 4 8 16 32 64 128 256 ... 2^k$
Les bretelles d'accès pour entrer dans cette autoroute, elles sont situées où : $ 16 64 256 .... 16* 4^k $
On démontre aisément qu'à chaque fois qu'on multiplie par 4, le nombre obtenu est égal à 1 modulo 3, et il a un enfant impair.
On a donc une première suite géométrique de raison 4, dans l'ADN de Collatz.
Les entiers impairs souches : Ce sont les entiers obtenus à partir de la suite précédente :
5=(16-1)/3
21=(64-1)/3
85=(256-1)/3
341=(1024-1)/3
On démontre aussi très facilement que pour passer d'un terme au suivant, on fait l'opération : $u_n+1 = 4u_n +1 $
On retrouve donc encore cette multiplication par 4, toujours dans l'ADN de Collatz.
On peut recommencer avec une autre autoroute, l'autoroute qui arrive sur 5 ( mais ça resterait valable pour celle arrivant sur 85, sur 341 ... sur n'importe quel entier impair )
L'autoroute qui arrive à 5, c'est 5 10 20 40 80 160 320 640.
Dans cette autoroute, il y a un terme sur 2 qui est égal à 1 modulo 3 ; ici, on a 10 40 160 640 ...
(donc on multiplie par 4 à chaque fois)
Et les entiers impairs qu'on obtient sont :
3 : 3*3+1 =10
13 : 3*13+1=40
53 : 3*53+1=160
213 : 3*213+1=640
Nos nombres 3 13 53 213 ... c'est à chaque fois : $u_{n+1} = 4*u_n +1$ 13 =4*3+1, 53=4*13+1 etc etc
Toi, tu l'as écrit sous une autre forme, moins exploitable : $ u_[n+1}-u_n = 4 ( u_n-u_{n-1} ) $
Mais c'est une conséquence de la relation précédente $u_{n+1} = 4*u_n +1$
Ici j'ai illustré les suites partant de 3, ou de 5 ... mais comme déjà dit, c'est valable partant de n'importe quel entier impair. (7,29,117,469.. . 11,45,161, 645 ... )
Cette suite arithmitico-géométrique $u_{n+1} = 4*u_n +1$ est complètement dans l'ADN de Collatz.
Et ces suites sont toutes infinies.
Ces suites, il me semble que tu les as dessinées déjà, dans le dessin de piste d'aéroport.
Au sein de chacune de ces suites ( 7,29, 117, 469 ... ) , tous ces nombres ont le même nombre d'étapes impaires. Et on ajoute 2 étapes paires à chaque nouvel entier.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
je vais regarder ça demain "à tête reposée" : il y a un truc avec deux aiguilles à coté de moi qui dit qu'il est 1h du mat ...
Juste pour ton info
les x sont bons pour 2, 3, 4, 5, 6
Je te sortirai les listes demain mais je remarque que les unités des i' ont des cycles en 7 ou 9, en en 1 ou 5 et celles du 2 se finissant toujousr par 3.
x = 7 ou 8 ne sont pas bons mais 9 et 10 le sont
à suivre -
ce que tu décris résume bien ma vision de la structure de Collatz : pour qu'un algorithme aussi simple ramène n'importe quel entier à 1, il faut une disponibilité de l'arithmétique pour le faire. : l'algorithme ne trace pas le chemin vers 1, l'algorithme ne connait pas tous les chemins vers 1 pour chacun des entiers. C'est évidemment impossible.lourran a écrit:Cette suite arithmitico-géométrique un+1=4?un+1 est complètement dans l'ADN de Collatz.
Les deux instructions possibles de l'algorithme de Collatz doivent simplement nous faire comprendre que les chemins sont ainsi faits qu'il suffit d'appliquer cette règle de conduite binaire pour aller à 1. C'est une illusion de la liberté de déplacement car il n'y a aucun degré de liberté : l'ensemble des entiers est pliable, retournable, dans un ordre très particulier qui ressemble à mon '"image radar de l’aéroport de Syracuse" ou de manière plus élaborée au fameux graph de Wikipedia
https://upload.wikimedia.org/wikipedia/commons/thumb/f/f1/All_Collatz_sequences_of_a_length_inferior_to_20.svg/330px-All_Collatz_sequences_of_a_length_inferior_to_20.svg.png
Et c'est bien ça l'adn de Collatz.
Ce que j'aime bien dans mon projet de modèle, c'est que finalement il oppose la simplicité de sa construction à la simplicité de l'algorithme : le record du nombre de démonstrations ''imbitables" appartient surement à la démonstration de la conjecture Collatz, et si ce n'est pas le cas, je parie que la conjecture est sur ce podium. Est-ce que leurs auteurs se sont posés une seule seconde comment deux instructions aussi simples pouvaient justifier des pages et des pages de formules ? Où est le rasoir d'Occam ?
Donc sans avoir le but d'être une démonstration, mon modèle pourrait par sa simplicité inspirer une démonstration simple. -
Pour revenir à des choses plus techniques, il existe dans ma bdd de 3 à 200.001 exactement 955 clusters avec le i' associé qui sont les cibles de mon modèle. Cette sélection est faite en filtrant i sur 5 et cluster_rank sur 1.
Ces clusters sont reliés à des valeurs successives de x de 1 à 132, puis 134, 136, 138, 141
Pour calculer correctement les coefficients, il faut au moins 4 clusters de référence (en me basant sur mon expérience). De ce fait, la liste des x à analyser :
2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103
donc j'appuie sur "run" et je reviens vers vous quand c'est cuit. Sans tuer le suspens, quelques coups de sonde m'ont déjà montré que certains x ne marchaient pas -
Quand tu as un nombre qui finit par 3, et que tu fais l'opération u'=4u+1, tu retombes sur un nombre qui finit par 3. Indéfiniment.
Quand tu as un nombre qui finit par 9, et que tu fais l'opération u'=4u+1, tu tombes sur un nombre qui finit par 7, et si tu refais l'opération u'=4u+1, tu retombes sur 9.
Donc alternance de 7 et 9.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
merci !
voici la liste des x ''testés positifs'' de 2 à 103
x = 2, 3, 4, 5, 6, 9, 10, 13, 19 (pour les détails, le pdf est joint.)
Si je teste le dernier i' prédit pour x = 19, cela me donne i' = 417081410803029 appartenant au cluster 19_75_5_98
et le script https://repl.it/repls/TenderGuiltyFolders#main.py me donne pour le même i' : x_n_i_tdv : 19_75_5_98 X:-(
Donc à ce jour le modèle est capable de donner une infinité de résultats fiables pour les clusters de x = 2, 3, 4, 5, 6, 9, 10, 13, 19
J'en profite pour renouveler ma demande : je cherche une personne disposée à prendre un peu de temps pour mettre en ligne un script python reprenant les formules du modèle Excel
(je tiens à dispo de cette personne une documentation précise des opérations à effectuer)
Je remarque pour les x qui ne marchent pas deux choses :
1) Pente v n'est pas égal à ln(4)
2) $v_{i_{0}}$ n'est pas un entier ou un entier + 1/2
Il faut donc débloquer ces deux points pour allonger la liste des x -
Voici une liste plus détaillée pour les x = 2, 3, 4, 5, 6, 9, 10, 13, 19
-
x , c'est bien le nombre d'étapes impaires ?
Sur quels critères dis-tu que tel x est 'testé positif' ?Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
LOURRAN a écrit:Sur quels critères dis-tu que tel x est 'testé positif' ?
Pour être reconnu positif, le x, ou plus précisément les séries de i' et de clusters associées à ce x et une série de n, doit passer une épreuve.
On rappelle d'abord que x est le nombre d'étapes impaires, entre i' et i (ces deux bornes incluses) de même que n est le nombre d'étapes paires entre les mêmes bornes.
Les explications concernent la liste de x positifs : x = 2, 3, 4, 5, 6, 9, 10, 13, 19
Première partie de l'épreuve.
Le modèle doit calculer exactement avec ses formules les différences des i' trouvés dans la bdd avec les critères de choix suivants :
a) i = 5, et cluster_rank = 1 (on ne cherche que les minorants de clusters)
b) à partir du plus petit n associé au x cherché, une suite de n de raison r =2 est générée
c) pour chaque x_n_i on cherche un i' dans la bdd on calcule les différences successeur - prédécesseur
d) et il faut que $\Large i' - i'_{-1} = v_{i_{0}}* e^{ln(4)*i'_{ref-1}}$
sachant que le modèle a trouvé la valeur de $v_{i_{0}}$ en calculant l'ordonnée origine des différences des i' de la bdd
e) mon test est déclaré positif si la somme des vraies différences est égale à celles des différences prédites
le test de correspondance valeur réelle (en gris) /valeur prédite (en bleu) :
https://imagizer.imageshack.com/img923/4889/dSjlS3.jpg
on continue les prédictions jusqu'à i_ref 20
https://imagizer.imageshack.com/img924/4468/MLS0iC.jpg
Sur ces deux tableaux, on voit bien que tous les différences des 7 premiers sont mêmes : leur somme est donc de 54610 dans les 2 cas,
Deuxième partie de l'épreuve.
J'utilise https://repl.it/repls/TenderGuiltyFolders#main.py pour que vérifier le dernier i' (ligne i'_ref =20) renvoie le même x_n_i_tdv que l'application de Raoul.
https://imagizer.imageshack.com/img922/9892/BPFJ0G.jpg -
Des nouveaux commencent à se débloquer comme x= 7 par exemple
La bonne nouvelle est que la formule reste la même ainsi que le paramètre ln(4)
$\Large i' - i'_{-1} = v_{i_{0}}* e^{ln(4)*i'_{ref-1}}$
La seul chose qu'il faut faire est de trouver la bonne série n associée au x que l'on cherche
Il peut y avoir des n qui partent d'un impair ou d'un pair
mais dans tous les cas, la raison de la suite n est égale à 2
la liste des nouveaux x dans l'apm... -
Pour finir la journée, voici la liste du modèle pour les x de 2 à 10
je donnerai quelques explications demain -
Ok , donc ta liste 2, 3, 4, 5, 6, 9, 10, 13, 19 est incomplète.
Je trouvais bizarre cette liste avec autant de trous.
Par exemple pour 15 , on a :
x n i' vérif
15 32 247
15 34 961 989
15 36 3845 3845
15 38 15381 15381
15 40 61525 61525
15 42 246101 246101
15 44 984405 984405
i' est le premier de cordée de chaque cluster.
La colonne 'vérif' est calculée avec : $4u_{n-1} +1 $ Par exemple 989=4*247+1
Au début , ça ne colle pas. Puis très vite, ça colle.
C'est pareil pour les valeurs de n impaires :
x n i' verif
15 31 123
15 33 481 493
15 35 1923 1925
15 37 7693 7693
15 39 30773 30773
15 41 123093 123093
15 43 492373 492373
15 45 1969493 1969493Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
Déjà 87 posts et 2 pages en 6 jours, ça promet.
Vous êtes bien partis pour battre votre précédent record qui est, je le rappelle, de 1226 messages, 25 pages, en à peu près 2 mois et demi.Après je bloque. -
i.Zitoussi a écrit:Vous êtes bien partis pour battre votre précédent record
J'aimerais surtout arriver à finir ce modèle. Le but de ce fil est de tenir un journal de cette "aventure", pas forcément de faire du "chiffre".
Cela se passe pas trop mal en ce moment puisqu'il y a une première collection de prédictions de clusters et i'. Mais il faut la compléter pour que le modèle n'apparaisse pas trop limité.
En tous cas, je trouve que c'est plus clair que le premier fil qui a fini par partir dans tous les sens. En ne parlant plus de démonstration mais de modèle on est plus dans le concret. N'hésitez pas à donner votre avis. -
@lourran
Donc je fais un point précis avec la dernière liste de couples clusters_i' que je viens de remette à,jour
Mon but en ce moment est surtout de trouver des paramètres qui garantissent que les prédictions de ces couples clusters_i' sont valides.
Je suppose que tu as pris connaissance de mes explications a méthode de validation qui est à mon sens très stricte.
http://www.les-mathematiques.net/phorum/read.php?43,2058452,2067162#msg-2067162
Aujourd'hui j'ai introduit un nouvel élément dans le modèle pour gérer la coupure que j'avais pour x = 7 et x = 8 de manière à avoir une première base continue de x = 2 à x = 10.
Le paramètre nouveau s'appelle $\text{trim } n_{0}$
Il modifie le $n_{0}$ de la suite $n$ qui est toujours de raison 2
Cette fonction Excel MIN.SI.ENS(DATA_n;DATA_x;x;DATA_clusterrank;1;DATA_i;5)+$\text{trim } n_{0}$ trouve le minorant $n$ de la plage du x cherché en éliminant aussi les i <>5.
Trois valeurs sont possibles pour ce trim : 0, 1, 2. Si par exemple pour x = 7 et trim = 0, le modèle affiche "négatif", il faut essayer x= 7 et trim = 1 et aussi x=7 et trim = 2, ce qui générera 2 nouvelles séries valides pour x = 7 associées avec des n impairs pour x = 1 et des n pairs pour x = 2.
Cette modification m'a permis de compléter les x 7 et 8 dont je rejoins le pdf mis à jour dans ce message. Ce trim permet aussi de trouver plus de clusters, mais il en manque encore 22
5_8_5_17 ___ 4_7_5_15 ___ 7_12_5_23 ___ 8_14_5_26 ___ 5_10_5_19 ___
9_17_5_30 ___ 4_9_5_17 ___ 5_12_5_21 ___ 9_19_5_32 ___ 4_11_5_19 ___
5_14_5_23 ___ 9_21_5_34 ___ 4_13_5_21 ___ 5_16_5_25 ___ 9_23_5_36 ___
4_15_5_23 ___ 5_18_5_27 ___ 9_25_5_38 ___ 4_17_5_25 ___ 5_20_5_29 ___ 9_27_5_40 ___ 4_19_5_27
x 2, 3, 6 et 10 sont complets. Il me manque une série pour les x 4, 5, 7, 9
Je conclus sur un point important. Ce modèle doit prendre racine dans une bdd. Et Il en sort les paramètres qui vont lui permettre de prédire des i' et des clusters quasi à l'infini (si un dev Python était fait). Une autre partie du modèle ne se sert pas du tout de la bdd, mais elle sait prédire que des clusters (sans les i'). -
En fonction des résultats de mon modèle pour x=2, il est possible de faire le tableau suivant :
(tableau qui découle du raisonnement de lourran ici :http://www.les-mathematiques.net/phorum/read.php?43,2058452,2066866#msg-2066866)
https://imagizer.imageshack.com/img924/4521/OLYbbJ.jpg
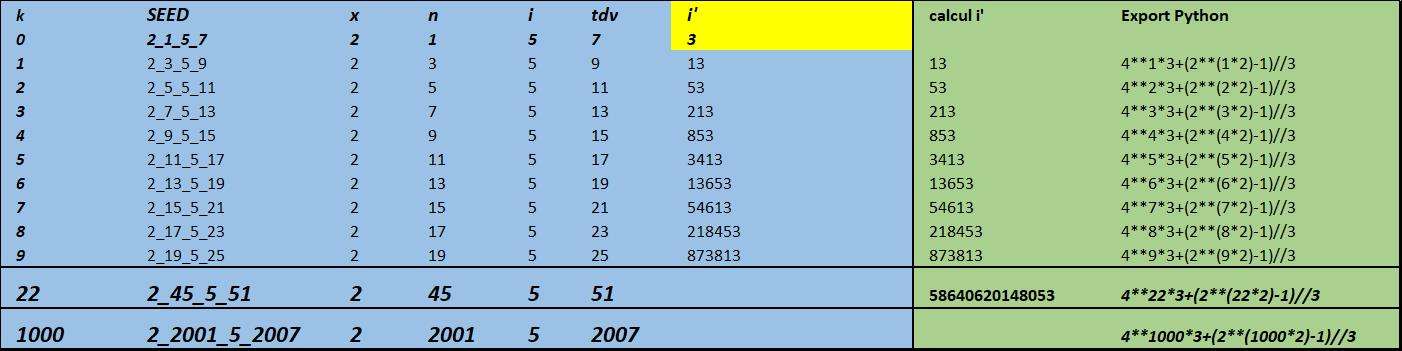
Le modèle montre une première chose : il existe des clusters "seed" ou source à partir desquels des séries infinies de clusters et de i' sont déclinables en suivant le même $x$ le même $i$ et des suites $n$ de raison $r_{n}$ et $tdv$ de raison $r_{tdv}$,
Le seed pour x=2 est 2_1_5_7
en analysant les données du modèle, la 23ème déclinaison de ce seed serait 2_47_5_53 pour un i' de 234562480592213,
ce qui est confirmé par https://repl.it/repls/TenderGuiltyFolders#main.py : x_n_i_tdv : 2_47_5_53
et la 1.000 ème déclinaison est :
x_n_i_tdv : 2_2001_5_2007
382710231758084841410944400392560661340772567362898400159214245608588753797456771
285553162105502089972815321546329154257815706320287685110475310452055551061797099
963817707600002295930494133482904763089966878287482605384878821294546491056753468
221179903016655193874662696482098685411038831787214073234442271147229696614861685
341264949359713529669782588334763342389022086101740027107454270972537559611057355
329984654727090072599528013473866177277505136298113006973068516525945298906797200
273190722101942517934751945753385094495954731440181696384252612942083918118429336
076142569393218179207282837163431253
ce calcul est fait par Python : print(10*(2**2000-1)//3+3)
c'est mon premier nombre de 603 chiffres, ce qui tendrait à démontrer que certains membres de ce forum plussoyassent un peu vite à mes dépends. (selon Sylvain Tesson (Sur les chemins noirs) il est important de savoir répondre aux plus basses injures dans un style châtié utilisant de préférence l'imparfait du subjonctif - donc acte)
C'est une avancée intéressante dans le domaine des suites de Collatz. Il est possible de prédire un cluster et son i' dès lors que le seed est connu.
Ceci s'explique très facilement : les données en bleu sont les sorties du modèle pour x= 2 mais pourrait aussi sortir d'une bdd de suites de Collatz pour x = 2. La différence entre 2 i' successifs est le point de départ. On va d'abord poser que
$\Large \iota = \frac {(i'-i'_{0})}{i'_{1}-i'_{0}}$
le ''iota" montre une suite de i (5,21,85,341...)
puis calculer $\ log_2{(3*\iota+1)}$ qui est une suite s = 2, 4, 6, 8, 10.... (s pour Syracuse évidemment)
et en calculant pour chaque terme $s$ de cette suite
$\Large i' = (i'_{1}-i'_{0})*(2^{s}-1)/i'_{0} + i'_{0}$
ce qui est à ma connaissance la première formule d'un calcul DIRECT de i'
en ayant en connaissance pour le seed 2_1_5_7
$ i'_{0} = 3$
$ i'_{1} - i'_{0} = 10$
la suite $s$ à partir de $s_{0} =2$ est de raison 2
du moins pour x = 2 ! -
La recherche de la formule du modèle pour x = 3 ne fonctionne pas avec la méthode du x=2
Mais la solution pour x=3 apporte une vraie amélioration par rapport à celle du x=2
Voici donc le tableau de x=3
https://imagizer.imageshack.com/img924/7104/7eE1ZR.jpg
Comme pour le tableau x=2, les cellules bleues viennent des prédictions du modèle mais pourraient aussi venir de la bdd
on a nommé k la numérotation de la succession des clusters (1ère colonne à gauche)
Le tableau est surtout plus simple et propose un calcul direct de i'
$\Large 4^k*i'_{0}+\frac {2^{2k}-1}{3}$
On remarquera donc que la seule donnée nécessaire au calcul de i' est $i'_{0}$
soit pour k = 1
x_n_i_tdv : 3_7_5_14
i' (formule python) = print( 4**1*17+(2**(1*2)-1)//3) = 69
ou k = 1000
x_n_i_tdv : 3_2005_5_2012
i' (formule python) = print(4**1000*17+(2**(1000*2)-1)//3) =
199009320514204117533691088204131543897201735028707168082791407716466151974677521
068487644294861086785863967204091160214064167286549596257447161435068886552134491
981185207952001193883856949411110476806782776709490954800136987073164175349511803
475013549568660700814824602170691316413740192529351318081909980996559442239728076
377457773667051035428286945934076938042291484772904814095876220905719530997749824
771592020458086837751754567006410412184302670875018763625995628593491555431534544
142059175493010109326071011791760249137896460348894482119811358729883637421583254
7595941360844734531877870753249842517
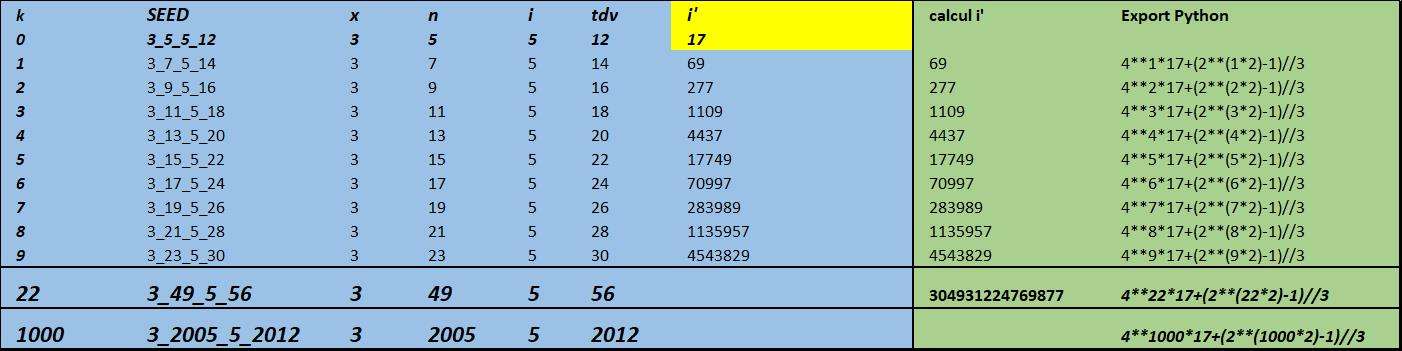
Pour la prédiction des clusters, la principe est également très simple
Soit une k une suite arithmétique de raison 1 avec $k_{0} = 0$
le cluster seed en $k_{0}$ = 3_5_5_12
- toutes les valeurs de x = 3 et i = 5 restent les mêmes quel que soit k
- la suite n débutant à 5 en $k_{0}$ est de raison 2 ou $\large tdv = tdv_{0}+2k$
- la suite tdv débutant à 12 en $k_{0}$ est de raison 2 ou $\large n = n_{0}+2k$ -
En remettant le x=2 sous cette nouvelle forme :
https://imagizer.imageshack.com/img924/7175/2bB2Cg.jpg
pour $ x = 2$
avec une suite k, suite arithmétique de raison 1 commençant en $k_{0} =0$
le cluster seed = 2_1_5_7
- x = 2 et i = 5 quel que soit k
- la suite n débutant à 5 est de raison 2 ou $tdv=tdv_{0}+2k$
- la suite tdv débutant à 12 est de raison 2 ou $n=n_{0}+2k$
et en vérifiant pour k = 1000
x_n_i_tdv : 2_2001_5_2007
i' (formule python) = print(4**1000*3+(2**(1000*2)-1)//3) =
382710231758084841410944400392560661340772567362898400159214245608588753797456771
285553162105502089972815321546329154257815706320287685110475310452055551061797099
963817707600002295930494133482904763089966878287482605384878821294546491056753468
221179903016655193874662696482098685411038831787214073234442271147229696614861685
341264949359713529669782588334763342389022086101740027107454270972537559611057355
329984654727090072599528013473866177277505136298113006973068516525945298906797200
273190722101942517934751945753385094495954731440181696384252612942083918118429336
076142569393218179207282837163431253 -
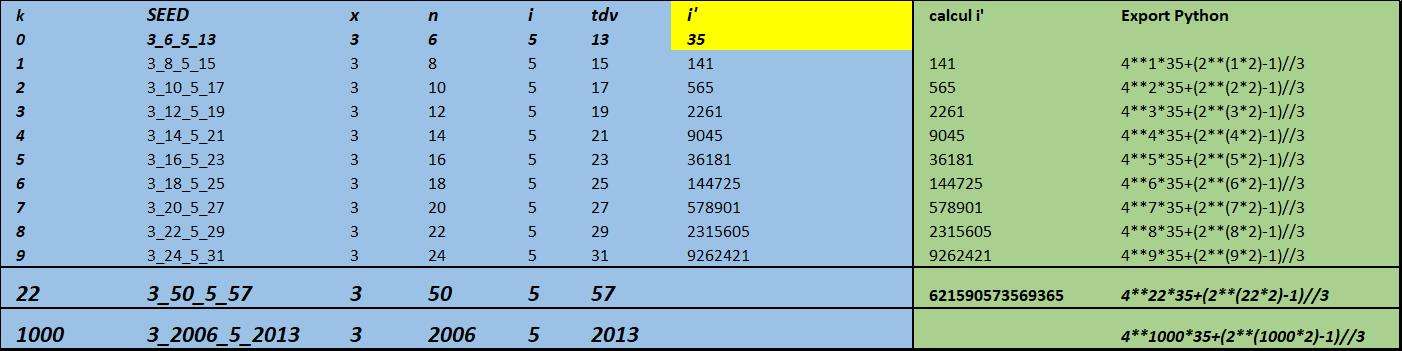
sans tout reprendre, voici le tableau x = 3 (n série n paire) pour le seed 3_6_5_13
en effet à partir de x=3 il y a deux tableaux par x, un pour les n pairs (trim n =1) et un pour les n impairs (trim n = 0)
https://imagizer.imageshack.com/img923/2742/NAp2KQ.jpg
pour k = 1000
x_n_i_tdv : 3_2006_5_2013
i' = print(4**1000*35+(2**(1000*2)-1)//3) =
405672845663569931895601064416114301021218921404672304168767100345104079025304177
562686351831832215371184240839108903513284648699504946217103829079178884125504925
961646770056002433686323781491879048875364890984731561707971550572219280520158676
314450697197654505507142458271024606535701161694446917628508807416063478411753386
461740846321296341449969543634849142932363411267844428733901527230889813187720796
649783734010715476955499694282298147914155444475999787391452627517502016841205032
289582165428059069010837062498588200165712015326592598167307769718608953205535096
2407111235568112699597198073932371285
Je pense avoir prouvé à ce stade que que le modèle Syracuse (surnom GODZILLA) est capable de prédire
des clusters et leurs i' (minorants de ces clusters) sans limite de taille (ou la limite de calcul de Python)
pour x = 2 et x = 3 que les séries n soient paire ou impaire.
Ce qui pour moi est tout de même une p... de satisfaction au vu du temps passé. -
Sachant que les racines de branches $i'_0$ s'écrivent sous une de ces deux formes: $i'_0=4n+3$ ou $i'_0=8n+1$
$4^ki'_0+\frac{4^k-1}{3}$ peut s'écrire comme $$
4^k(4n)+\frac{10\cdot4^k-1}{3}\qquad\text{ou}\qquad4^k(8n)+\frac{4\cdot4^k-1}{3}
$$ voir ici
Les autres nombres ($j>0$) sont de la forme $i'_j=8n+5$ pour les deux types de branches. -
J'ai validé aujourd'hui plusieurs éléments fondamentaux du modèle, à savoir une méthode permettant de prédire à partir d'un seed des séries de clusters et de i' avec des résultats parfaitement exacts même avec des grands nombres.
De ce fait, j'ai pu m'occuper de la construction technique du modèle en enlevant tout ce qui est superflu et en optimisant son organisation pour obtenir une interface agréable.
Je suis donc arrivé à un modèle basé sur 3 modules :
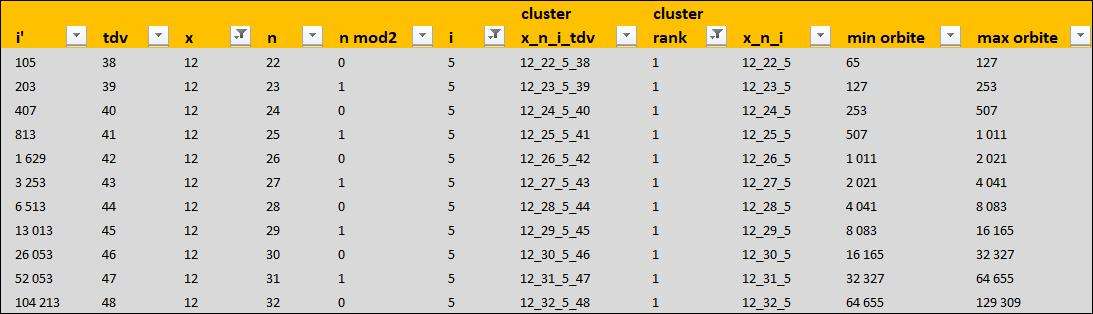
- le module BDD qui contient les i' de 3 à 200.0001 sur lequel je n'ai gardé que
i' ___ tdv ___ x ___ n ___ n-mod2 ___ i ___ x_n_i_tdv ___ cluster-rank ___ x_n_i ___ min orbite ___ max orbite
(n-mod2 sert à connaitre la parité de n, cluster-rank indique la position du i' dans son cluster)
- le module X-FILES va sortir de la BDD une série n selon le choix d'un x et de la parité de n
Cette sélection se fait avec par défaut i = 5 et cluster-rank = 1
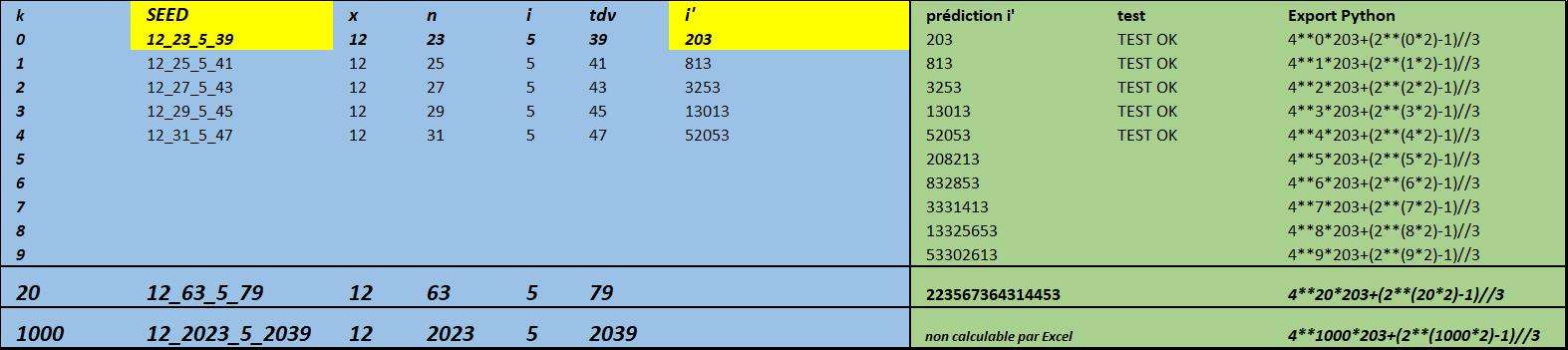
- le module SEED-X va entrer en x, n, i, tdv et i' ce qui est sélectionné par X-FILES. Il va vérifier que les i' prédits sur cette série sont les mêmes que les i' réels. Les i' prédits sont traduits en code Python prêts à être copiés dans un site de calcul python en ligne comme https://repl.it/repls/TenderGuiltyFolders#main.py
Les clusters associés au i' sont également prédits par ce module.
Les deux dernières lignes sont k 20 qui est le l' maximum calculable par Excel et K1000 qui ne peut être calculé que par Python
Chaque vérification du K1000 sur https://repl.it/repls/TenderGuiltyFolders#main.py permet d'être certain que ça marche.
En y associant une macro, cette nouvelle version du modèle (surnom XFILES) va rapidement donner la centaine de x de la bdd actuelle. Quand le pdf de cette liste sera disponible, les bonnes volontés pour effectuer les vérifications Python seront les bienvenues.
Je pense à ce stade être arrivé à un bon pourcentage de mon objectif initial.
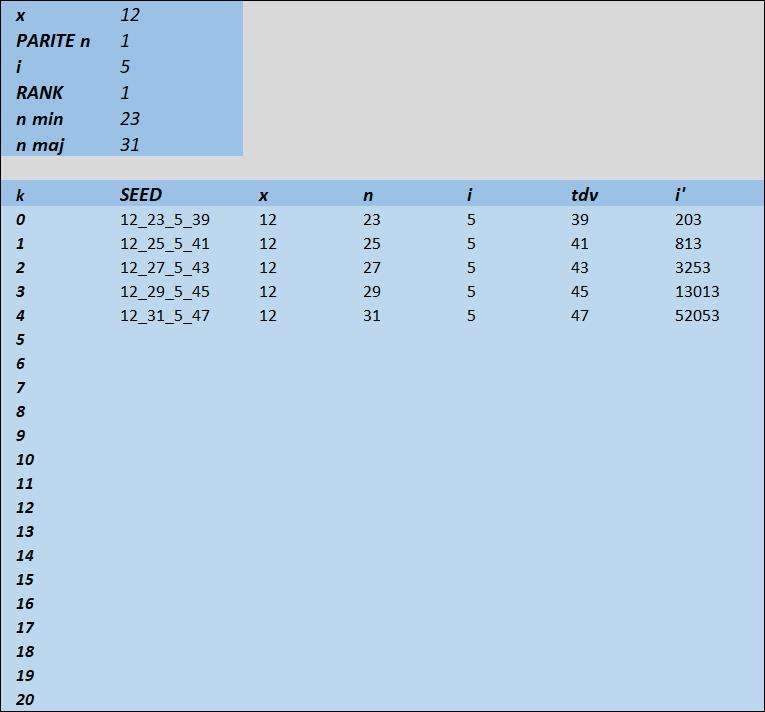
Voici les interfaces, réglées pour x =12
https://imagizer.imageshack.com/img923/3435/44eyuG.jpg
https://imagizer.imageshack.com/img924/4918/4IBy3x.jpg
https://imagizer.imageshack.com/img922/972/tJgDCw.jpg
le calcul Python du k1000 identique à la prévision
x_n_i_tdv : 12_2023_5_2039
23345324137243175326067608423946200341787126609136802409712068982123913981644863048418742888435627488341734614326
07840972675808553754879173899393757538861476962309779288016360014005176014214245719054848797957553643892847760809
89673359544619615614919740840159668263544244854080198100733687390200584673009785399810114935065628058171619109425
25309856737888420563885730347252206141653554710529324791136274498675129063938352494428571208821905836813927813314
18489342535717950808266323331462921666463404821849359401986869095649076425323861785108347943940938946711900522418
9500644696732986308931644253066969306453 -
collag3n a écrit:Sachant que les racines de branches i?0 s'écrivent sous une de ces deux formes....
Je vais désormais entrer ce test dans le modèle.
$ i'_{0}=4n+3 $ correspond à une suite n impaire
$ i'_{0}=8n+1 $ correspond à une suite n paire
Exemple pour x = 50
SEED : 50_86_5_140 n = 86, 88, 90, 92_______ $i'_{0} = 1441 = 8n+1$
SEED : 50_85_5_139 n = 85, 87,89, 91, 93_____$i'_{0} = 731 = 4n+3$
Ce choix binaire impliquerait forcément que tous les minorants de clusters $i'_{0}$ sont sous une de ces deux formes
Je ne comprends pas la deuxième partie de ton message.
A quoi correspond $4^ki'_0+\frac{4^k-1}{3}$ ?
A part ça bien content de te retrouver sur ce fil. Mon modèle est quasi fonctionnel car il va pouvoir analyser en masse des bdd (je vise une centaine de x pour commencer) et donner pour chacun les "seed" qui permettent de prédire clusters et i' aussi grands qu'on veut (limite de calcul de Python). Donc j'espère que tu seras sur ce fil dans les jours qui suivent. -
Un autre intérêt d'écrire sous deux formes, est que le parent (via la forme compressée de la fonction collatz $f(x)=\frac{3x+1}{2^j}$) d'un nombre $4^k(4n)+\frac{10\cdot4^k-1}{3}$ est $6n+5$ (même $n$, quelque soit la valeur de $k$) et le parent de $4^k(8n)+\frac{4\cdot4^k-1}{3}$ est $6n+1$ (même $n$, quelque soit la valeur de $k$)
-
En d'autres mots : $2^{2k}$ est égal à $4^k$ Et c'est quand même beaucoup plus élégant d'écrire $4^k$Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin
-
@collag3n
ok je comprends ! (il est tard visiblement pour mes neurones)
Tu as ré-écrit ma formule sous deux formes. Je suppose que tu as gardé mes notations pour k et n. Je testerai donc ces 2 formes dans le modèle
J'ai une question pour finir :
certains $i'_{0}$ me posent problème comme le 11 car la formule ne marche pas
as-tu une explication ?













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Connectez-vous ou Inscrivez-vous pour répondre.
Bonjour!
Catégories
- 163.2K Toutes les catégories
- 9 Collège/Lycée
- 21.9K Algèbre
- 37.1K Analyse
- 6.2K Arithmétique
- 53 Catégories et structures
- 1K Combinatoire et Graphes
- 11 Sciences des données
- 5K Concours et Examens
- 11 CultureMath
- 47 Enseignement à distance
- 2.9K Fondements et Logique
- 10.3K Géométrie
- 65 Géométrie différentielle
- 1.1K Histoire des Mathématiques
- 69 Informatique théorique
- 3.8K LaTeX
- 39K Les-mathématiques
- 3.5K Livres, articles, revues, (...)
- 2.7K Logiciels pour les mathématiques
- 24 Mathématiques et finance
- 314 Mathématiques et Physique
- 4.9K Mathématiques et Société
- 3.3K Pédagogie, enseignement, orientation
- 10K Probabilités, théorie de la mesure
- 773 Shtam
- 4.2K Statistiques
- 3.7K Topologie
- 1.4K Vie du Forum et de ses membres
In this Discussion
Qui est en ligne 1
1 Invité