Un modèle pour Syracuse

Bonjour à tous
Je vous présente un modèle mathématique des suites de Syracuse et ses premiers résultats.
Selon wikipedia : Un modèle mathématique est une traduction d'une observation dans le but de lui appliquer les outils, les techniques et les théories mathématiques, puis généralement, en sens inverse, la traduction des résultats mathématiques obtenus en prédictions ou opérations dans le monde réel.
On remarquera que dans ce cas, on observe les suites de Syracuse comme des objets du monde réel, puis ces observations produisent un ensemble des formules dont on peut tirer des prédictions. On a donc ''objectiver'' les maths pour créer des nouveaux outils mathématiques.
Les formules du modèle doivent être totalement indépendantes de l'algorithme de Syracuse. D'une manière générale l'algorithme va dans le sens ''descendant'' d'un entier vers 1 tandis que le modèle va dans le sens ascendant du premier impair rencontré jusqu'à l'entier impair i' de départ de la suite.
Le modèle n'est pas une démonstration de la Conjecture, mais il amène à celle-ci un éclairage nouveau. Tout dépendra donc de l'évolution de ce modèle pour aider à la construction d'une démonstration en s'inspirant de ses propriétés.
Dans le cas le plus simple, le modèle part d'une suite arithmétique k de raison r et donne une suite d'entiers impairs associés à une autre suite de variable des suites de Syracuse.
La notification de ces variables est :
i' : entier impair de départ et par extension toute étape impaire jusqu'a 1
x : nombre d'étapes impaires i' à i
n : nombre d'étapes paires i' à i
i : dernière étape impaire avant 1 tel que $3i+1 = 2^{m} \text{ avec m} = log_2{(3i+1)}$
tdv : le temps de vol de i' à 1 (conforme aux tdv du site calculis https://calculis.net/syracuse )
$tdv = x + n + m$
Le modèle en est à ses débuts en manière de prédictivité, le travail préalable ayant été la constitution d'une bdd des suites et leur analyse en détail (ref fil : http://www.les-mathematiques.net/phorum/read.php?43,1993402,1993402#msg-1993402)
Voici donc les tout premiers résultats de ce modèle
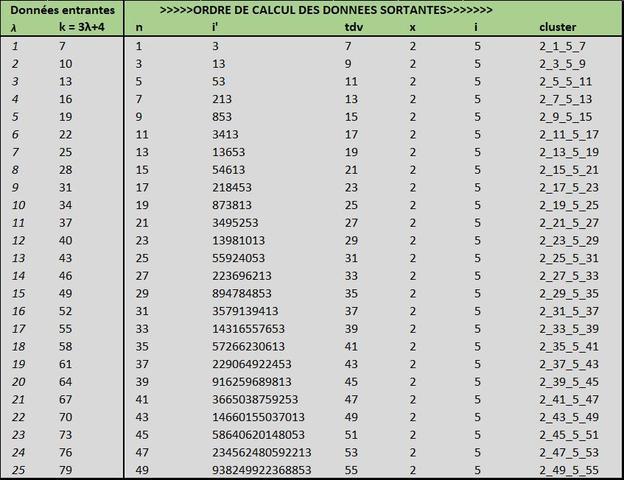
Pour k = 7, 10, 13, 16, 19, 22, 25, 28
donc une simple suite de raison 5 avec $k_{0} = 7$ qui en elle-même n'a aucun rapport avec les suites de Collatz.
On obtient en calculant
$ \large n = \frac{2}{3}*k-\frac{11}{3} = 1, 3, 5, 7, 9, 11, 13, 15 $
$\large i' = \frac{1}{24}*(5*2^{\frac{2(k-1)}{3}}-8) = 3, 13, 53, 213, 853, 3413, 13653, 54613$
Ces deux formules sont totalement indépendantes de l'algorithme de Syracuse puisqu'elle n'utilise que la variable k
La bdd dit que ces i' appartiennent aux clusters x_n_i_tdv :
2_1_5_7______2_3_5_9______2_5_5_11______2_7_5_13______2_9_5_15______2_11_5_17______2_13_5_19______2_15_5_21
les clusters sont des collections de i' selon leurs valeurs x, n, i et tdv, le triplet x,n,i étant un classificateur des i' ayant le tdv de ce cluster
Je vous présente un modèle mathématique des suites de Syracuse et ses premiers résultats.
Selon wikipedia : Un modèle mathématique est une traduction d'une observation dans le but de lui appliquer les outils, les techniques et les théories mathématiques, puis généralement, en sens inverse, la traduction des résultats mathématiques obtenus en prédictions ou opérations dans le monde réel.
On remarquera que dans ce cas, on observe les suites de Syracuse comme des objets du monde réel, puis ces observations produisent un ensemble des formules dont on peut tirer des prédictions. On a donc ''objectiver'' les maths pour créer des nouveaux outils mathématiques.
Les formules du modèle doivent être totalement indépendantes de l'algorithme de Syracuse. D'une manière générale l'algorithme va dans le sens ''descendant'' d'un entier vers 1 tandis que le modèle va dans le sens ascendant du premier impair rencontré jusqu'à l'entier impair i' de départ de la suite.
Le modèle n'est pas une démonstration de la Conjecture, mais il amène à celle-ci un éclairage nouveau. Tout dépendra donc de l'évolution de ce modèle pour aider à la construction d'une démonstration en s'inspirant de ses propriétés.
Dans le cas le plus simple, le modèle part d'une suite arithmétique k de raison r et donne une suite d'entiers impairs associés à une autre suite de variable des suites de Syracuse.
La notification de ces variables est :
i' : entier impair de départ et par extension toute étape impaire jusqu'a 1
x : nombre d'étapes impaires i' à i
n : nombre d'étapes paires i' à i
i : dernière étape impaire avant 1 tel que $3i+1 = 2^{m} \text{ avec m} = log_2{(3i+1)}$
tdv : le temps de vol de i' à 1 (conforme aux tdv du site calculis https://calculis.net/syracuse )
$tdv = x + n + m$
Le modèle en est à ses débuts en manière de prédictivité, le travail préalable ayant été la constitution d'une bdd des suites et leur analyse en détail (ref fil : http://www.les-mathematiques.net/phorum/read.php?43,1993402,1993402#msg-1993402)
Voici donc les tout premiers résultats de ce modèle
Pour k = 7, 10, 13, 16, 19, 22, 25, 28
donc une simple suite de raison 5 avec $k_{0} = 7$ qui en elle-même n'a aucun rapport avec les suites de Collatz.
On obtient en calculant
$ \large n = \frac{2}{3}*k-\frac{11}{3} = 1, 3, 5, 7, 9, 11, 13, 15 $
$\large i' = \frac{1}{24}*(5*2^{\frac{2(k-1)}{3}}-8) = 3, 13, 53, 213, 853, 3413, 13653, 54613$
Ces deux formules sont totalement indépendantes de l'algorithme de Syracuse puisqu'elle n'utilise que la variable k
La bdd dit que ces i' appartiennent aux clusters x_n_i_tdv :
2_1_5_7______2_3_5_9______2_5_5_11______2_7_5_13______2_9_5_15______2_11_5_17______2_13_5_19______2_15_5_21
les clusters sont des collections de i' selon leurs valeurs x, n, i et tdv, le triplet x,n,i étant un classificateur des i' ayant le tdv de ce cluster
Réponses
-
Le but du modèle est d'identifier un cluster x_n_i_tdv et donc de prédire à partir de k les variables x, n, i, tdv
On rappelle qu'un tdv et un seul s'associe au triplet x,n,i,
Le modèle est à ce jour capable de calculer les variables x, n, i, tdv pour la suite k = 7, 10, 13, 16, 19, 22, 25, 28
1) Le modèle impose de calculer d'abord n, i' et tdv directement depuis k
$\large n = \frac{2}{3}*k-\frac{11}{3} = 1, 3, 5, 7, 9, 11, 13, 15$
$\large i' = \frac{1}{24}*(5*2^{\frac{2(k-1)}{3}}-8) = 3, 13, 53, 213, 853, 3413, 13653, 54613$
$\large tdv = \frac{4k+ \text {k mod3}* (29-15*\text {k mod3})}{6} = 7, 9, 11, 13, 15, 17, 19, 21$
En Excel : tdv = (4*k+MOD(k;3)*(29-15*MOD(k;3)))/6
2) puis de déduire x et i des calculs de n, i' et tdv
$\large x = \lfloor log_6{2^{tdv/i'}} \rceil = 2, 2, 2, 2, 2, 2, 2, 2$
$\large i = \frac{2^{tdv-x-n}-1}{3} = 5, 5, 5, 5, 5, 5, 5, 5$
En Excel x = arrondi(log(2^tdv/i';6);0) et i =(2^(tdv-x-n)-1)/3
La suite k = 7, 10, 13, 16, 19, 22, 25, 28 a donc permis de trouver 8 i' :
3,13,53,213,853,3413,13653,54613 appartenant aux clusters 2_1_5_7______2_3_5_9______2_5_5_11______2_7_5_13______2_9_5_15______2_11_5_17______2_13_5_19______2_15_5_21 -
BonjourPMF a écrit:Pour k = 7, 10, 13, 16, 19, 22, 25, 28
donc une simple suite de raison 5 avec k0=7 qui en elle-même n'a aucun rapport avec les suites de Collatz.
tu veux dire une suite arithmétique du premier terme U0 = 7 , et de raison 3 , soit le terme général Up = 7+ 3.p;
d’où U0 = 7 , U1=7+3.1 =10 , U2=7+3.2 =13 ,......ext .
en posant n = "le nombre de division par 2 de i' à i " , avec i' le premier terme impair du départ de la suite de Collatz , et i l'avant dernier impair avant le 1 ( qui définit une sous suite de Collatz entre i à 1 ).
d’où d’Après votre première formule indépendante de la suite de Collatz - ce qui la rend intéressante- mais d'on ignore totalement l'origine explicatif ( idem pour votre deuxième formule ) ? :
n = 2/3.(Up) - 11/3 donc n devient une suite dont n0= 1 , n1=3 , n2=13 , n3=53 , n4=213 .....ext
d’où la question trivial : n progresse par rapport à quoi ?
pour moi , une formule demeure suspecte** tant qu'on a pas défiler toute la suite de raisonnements explicatifs qui justifie son utilisation dans le modèle expérimentale proposé pour approcher la Suite de Collatz
** suspecte , surtout quand elle émane de la part d'intervenants dont on connait d'avance la "position idéologique"
BERKOUK -
Bonjour Berkouk
Il faut vraiment prendre un modèle pour ce qu'il est : un processus de calcul , un programme si l'on veut, dans lequel on a des données en entrée et des résultats en sortie.
Si je veux te vendre une voiture, je vais te proposer de l'essayer pour que tu juges qu'elle marche bien. Mais tu n'as pas besoin de savoir comment fonctionne le moteur. Sur ce un nouveau fil de discussion on se basera sur le modèle de son point de départ à (je l'espère) son point d'arrivée, et je ne parlerai que du modèle.
La suite de données en entrée cela peut très bien être 1,2,3,4,5.... si on veut. Il faut surtout qu'à aucun moment le modèle puisse être soupconné de prendre des résultats dans les suites de Collatz. Le modèle ne sait pas ce que c'est qu'une suite de Collatz, c'est toi ou moi qui le savons. Il n'utilise jamais l'aglorithme de Collatz. Jamais, jamais, jamais !
Je donnerai bien sûr les formules qui permettent les calculs, comme dans mes deux premiers messages. Pour te permettre de physiquement vérifier qu'une suite de résultats i', x, n, i, tdv sortant du modèle sont les mêmes des i', x, n, i, tdv des suites de Collatz.
Je ne vais donc pas batailler sur les mêmes points que le premier fil de discussion. Un modèle n'a pas besoin d'être démontré. Je publie avec toutes les informations nécessaires une sorte de journal de la fabrication de ce modèle. Comme j'en suis le designer, c'est à moi de choisir telle formule plutôt qu'une autre (c'est de la pure mécanique). Ce qui m'intéresse de toi ou de la part des mathématiciens sur ce forum, c'est de savoir ce qui vous intéresse dans les résultats, quelle porte cela pourrait ouvrir. Je voudrais surtout vous interpeller sur l'interprétation théorique.
Ma théorie à ce stade de la fabrication du modèle est celle-ci : le modèle va dans le sens générationnel (ascendant i à i') en faisant autre chose que de prendre à l'envers les chemins des suites de Collatz, que j'appelle le sens généalogique (descendant de i' à i). Il crée donc des suites de i', de n, de x et de tdv à sa façon. On utilise évidemment les mêmes termes que ceux de Collatz, mais absolument pas l'algorithme ou les formules qui lui sont reliées.
Le deuxième point théorique concerne les maths et le monde réel. Quand je compile une bdd des suites de Collatz, je matérialise si on veut le produit de l'algorithme de Collatz en données réelles, qui pourraient être les données de la croissance des haricots verts, ou celles du nombre de points sur les élytres d'une coccinelle ! Ces données acquises sont traitées avec des méthodes de data mining (ma compétence). Puis j'élabore mon modèle pour qu'il reproduise des suites identiques à celles de Collatz mais en faisant comme si l'algorithme n'existait pas. De cette manière je fait une nouvelle mathématisation des données comme c'est le rôle de tous les modèles existants à ce jour.
Donc mon cher Berkouk, je te donnerai tout ce qu'il faut pour que les formules ne te paraissent pas suspectes mais tu devras comprendre la différence entre tout ce qui ressemblerait à une démonstration de la conjecture et ma démarche qui remathématise les données. Un nouveau fil de discussion doit absolument trancher avec le précédent où j'avoue que cette frontière n'a jamais été très claire. Mais elle l'est maintenant. Je ne suis pas en train de faire une démonstration ou simili-démonstration. Je suis finalement dans la peau de Collatz avant qu'il n'invente son algorithme. J'essaie de faire un "truc" qui va produire une série infinie de chemins d'entiers qui reviennent à 1. Comme l'algorithme n'est virtuellement pas inventé, je choisis la méthode que je veux.
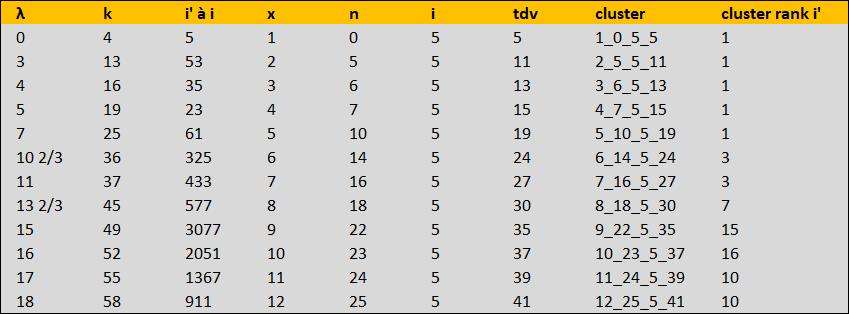
J'en profite donc pour te donner une ''rallonge'' aux 8 premiers i'. On va encore faire plus simple avec la suite de départ : 1,2,3,4,5... qui drive maintenant k avec une petite relation toute simple. Je signale que j'ai vérifié avec le script de Raoul S la cohérence des x_n_i_tdv (je t'encourage à le vérifier par toi-même). Je signale aussi que je ne peux pas dépasser 10^15 avec Excel qui est l'application utilisée par mon modèle.
Voici les données telles qu'elles sont affichées sur Excel
https://imagizer.imageshack.com/v2/1024x768q90/922/PZbOXI.jpg
et les formules utilisées :
$\lambda$ : de 1 à 25 on ne peut pas faire plus simple
k = 3$\lambda$+4
n = ((2/3)*k-(11/3))
i' =(1/24)*(5*2^(2*(k-1)/3)-8)
tdv = = (4*k+MOD(k;3)*(29-15*MOD(k;3)))/6
x = ARRONDI(LOG(2^tdv/i';6);0) : pour la lisibilité, je j'utilise tdv et i' mais on peut leur substituer leurs formules basées sur k
i =(2^(tdv-x-n)-1)/3 : pour la lisibilité, même remarque
cluster : concaténation x,n,i, tdv
Voilà tu en sait autant que moi sur ce modèle ! -
i' =(1/24)*(5*2^(2*(k-1)/3)-8)
pour k=3l+4 , I (lumbda) =30 donc k = 94
i' = (1/24)*(5*2^2*(94-1)/3)-8)
= (1/24)*(5*2^54)
= 90071992547409920/24
i' = 3752999689475413.33 : nombre décimale ? ya-t-il des arrondis ?
BERKOUK -
Bonsoir Berkouk
Après vérification, toutes les valeurs du tableau pour $\lambda$ <= 25 sont bien entières (équivalent de k de 7 à 79)
On remarquera d'ailleurs que seule la formule de x force un arrondi, pas les autres
Quand $\lambda$ dépasse 25, j'arrive dans les zones ''dangereuses'' d'Excel pour i' qui atteint les 10^15 (c'est la limite)
donc je ne peux pas le calculer.
Il faudrait faire des essais sur Python pour être sûr des calculs de $\lambda$>25
Merci de ton attention -
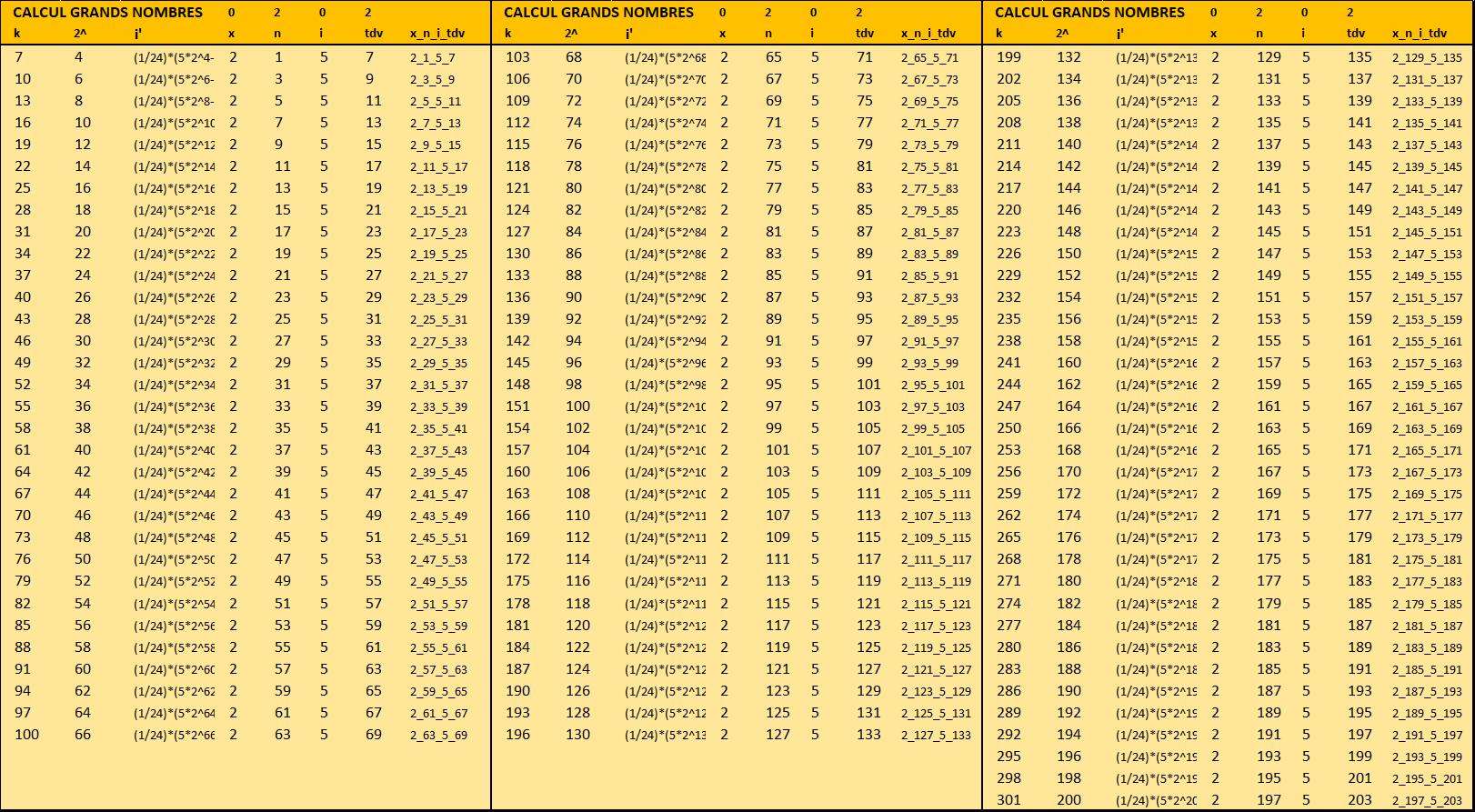
Suite à la demande de Berkouk, j'ai donc fait un coup de sonde au delà des 10^15
J'ai donc fait une version ''modèle grand nombre'' du modèle en contournant ce problème d'Excel
Comme Berkouk était interessé par $k=94 \text{ pour } \lambda = 30}
i' sera affiché ainsi : (1/24)*(5*2^62-8)
Dans le script en ligne https://repl.it/repls/EthicalTangibleLocations#main.py
je peux entrer directement i' en ligne 25 : i_prime = (1/24)*(5*2**62-8)
ce qui retourne le résultat : x_n_i_tdv = 2_59_5.0_65
Sur mon 'modèle grand nombre'' le résultat est 2_59_5_65
Voilà les données en poussant jusqu'à k = 301 : Cliquer dessus ça sera plus beau.
https://imagizer.imageshack.com/img924/8141/T6G8fK.jpg -
Il faut prendre de la hauteur. Tu as des arguments pour répondre à Berkouk :
$ \forall \lambda \in \N, i' = (2^{(tdv-x-n)}-1)/3 \in \N $
Tu peux l'expliciter autrement,
Soit $S$ la fonction de $\N^*$ dans $\N^*$, définie par : si $n$ est un entier impair $S(n)=3n+1$, sinon $S(n)=n/2$ (S est la fonction de Syracuse)
On vérifie aisément que l'image de tout entier strictement positif est bien un entier strictement positif.
Pour simplifier l'analyse, on va convenir que $S(1)=0$
Lemme n°1 :
Pour tout entier n, il existe au moins un n' tel que S(n')=n, il suffit de prendre $n'=2n$.
Et pour tout entier $n$ de la forme $n=6k+4$, il existe un second entier $n'$ tel que $S(n')=n$, cet autre entier $n'$ est $n'=(n-1)/3$
Seuls les entiers de la forme n=6k+4 ont 2 antécédents par la fonction S.
Exemple :
$S(3)=10$ ; $S(S(3)=S^2(3)=5$ ; $S^3(3)=16$ ; $S^4(3)=8$ ; $S^5(3)=4$ ; $S^6(3)=2$ ; $S^7(3)=1$
10 est de la forme $6k+4$, il a donc 2 antécédents : 3 et 20.
Conjecture de Syracuse :
Il semblerait que $\forall n \in \N^* , \exists k \in \N , S^k(n)=1 $
On va noter $\N_1 = \{ n \in \N^* , \exists k \in \N , S^k(n)=1 \} $ et $ \N_2 = \N - \N_1 $
Selon la conjecture de Syracuse, on aurait donc $\N_1=\N$ et $\N_2 = \{\} $
Notation : si $ n \in \N_1 $ on note $tdv(n) = \min \{k \in \N , S^k(n) = 1 \} $ ; la fonction $tdv$ est la fonction 'temps de vol'.
Exemple : $tdv(2) =1$ ; $tdv(3) = 7$
Par convention, $tdv(1) =0$
La fonction $tdv$ est définie pour tous les éléments de $\N_1$
Lemme n°2 :
$\forall n \in \N_1 , S(N) \in \N_1 $
Lemme n°3
$\forall n \in \N_1 , \forall k \in \N , n*2^k \in \N_1 $ et $ tdv(n*2^k) = tdv(n)+k $
Lemme n°4 ( ce lemme n°4 est plus ou moins le contenu de ton tableau, généralisé à "plein d'entiers")
$\forall n \in \N_1 , mod(n)=1 \Rightarrow 4n+1 \in \N_1 $ et $ tdv(4n+1) = tdv(n)+2 $
En 'français' : si $n$ est un entier impair, et si $n$ appartient bien à $\N_1$, alors $4n+1$ appartient aussi à $\N_1$, et $tdv(4n+1) = tdv(n)+2$
Démonstration :
Soit n un entier impair
$S(N) = 3n+1$
$4*S(n) = 12N+4$ est un entier de la forme $6k+4$ et donc, il existe $n_0$ impair , tel que $3 n_0+1 = 6k+4 $
On vérifie aisément que si $n_0=4n+1$ alors $S(n_0) = 3n_0+1 = 12n+4= 4S(n)$
Et du coup, $4n+1 \in \N_1$
tdv(4n+1)= ?
$tdv(4n+1) = tdv( S(4n+1) ) +1 = tdv ( 4 S(n) ) +1 = tdv(S(n))+3 = tdv(n)+2 $
Pas besoin de Python ou de quoi que ce soit pour étendre les calculs au delà de 25 ... Par des calculs tout simples comme ceux ci-dessus, tu peux démontrer 'par récurrence' plein de choses.
Et 'par récurrence', ce n'est pas un gros mot, c'est une méthode de démonstration courante dans les questions d'arithmétique.
En fait, dans ce lemme n°4, au lieu d'exprimer $i'$ à partir des autres nombres de la même ligne, j'exprime $i'$ à partir du $i'$ de la ligne du dessus. Et je démontre (oui, démonstration) que ce $i'$ est bien lui aussi dans mon ensemble $\N_1$ et je démontre aussi qu'il a un tdv égal à 2 plus le tdv du i' précédent.
Mais, pour te faire redescendre sur terre, ça, c'est un truc qu'un bon lycéen au fond du Larzac sans connexion internet va trouver et démontrer au bout de 2 jours de réflexion sur la conjecture de Syracuse.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
Hello Raoul
merci !
donc en testant sur https://repl.it/repls/EthicalTangibleLocations#main.py
i_prime = (5*2**62-8)//24 >>>> Resultat : x_n_i_tdv : 2_59_5_65
print((5*2**62-8)//24) >>>>>> Resultat : 960767920505705813
et dans mon modèle ''grand nombre"
k__________2^__________i'_______________________x__________n___________i___________tdv__________x_n_i_tdv
94_________62__________(1/24)*(5*2^62-8)__________2__________59__________5__________65__________2_59_5_65
https://calculis.net/syracuse
960767920505705813 - 2882303761517117440 - 1441151880758558720 - 720575940379279360 - 360287970189639680 - 180143985094819840 - 90071992547409920 - 45035996273704960 - 22517998136852480 - 11258999068426240 - 5629499534213120 - 2814749767106560 - 1407374883553280 - 703687441776640 - 351843720888320 - 175921860444160 - 87960930222080 - 43980465111040 - 21990232555520 - 10995116277760 - 5497558138880 - 2748779069440 - 1374389534720 - 687194767360 - 343597383680 - 171798691840 - 85899345920 - 42949672960 - 21474836480 - 10737418240 - 5368709120 - 2684354560 - 1342177280 - 671088640 - 335544320 - 167772160 - 83886080 - 41943040 - 20971520 - 10485760 - 5242880 - 2621440 - 1310720 - 655360 - 327680 - 163840 - 81920 - 40960 - 20480 - 10240 - 5120 - 2560 - 1280 - 640 - 320 - 160 - 80 - 40 - 20 - 10 - 5 - 16 - 8 - 4 - 2 - 1
La durée du vol pour 960767920505705813 est de 65 et son altitude est de 2882303761517117440.
Donc le modèle semble bien fonctionner avec d'assez grands nombres ! -
@lourran
merci pour ce soutien mathématique. Très utile pour moi et pour bon nombre de lecteurs de ce fil, je pense.
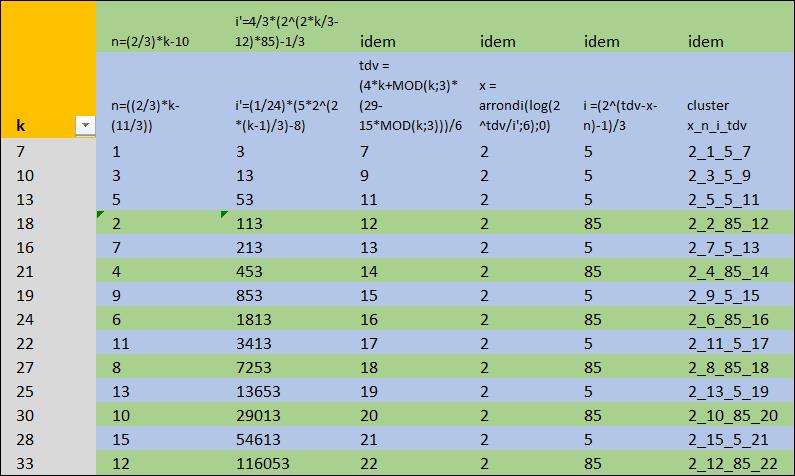
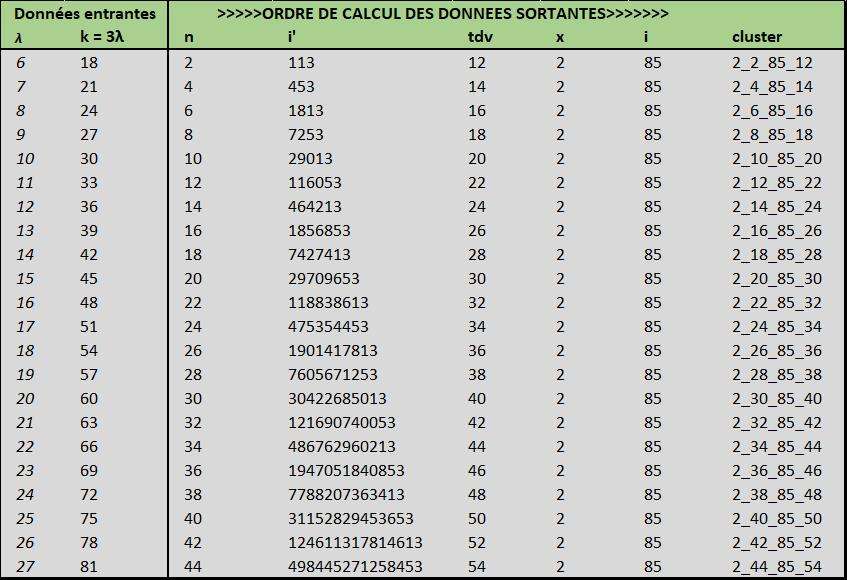
Je continue le développement du modèle, j'ai maintenant la clé pour modéliser les suites en x=2 et i =85, d'où va se décliner un calcul général pour toutes les formes de i (enfin j'espère)
En version brouillon, ça donne ça (les formules des i = 85 sont dans les cases vertes mais en version non simplifiées)
https://imagizer.imageshack.com/img923/8450/aeyjvk.jpg -
Bien entendu qu'il fonctionne... lis ma démonstration 2 messages plus haut.
Il ne sert à rien, mais il fonctionne.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
je vais essayer de bien comprendre cette démonstration, et voir toutes ses interactions avec le modèlelourran a écrit:Bien entendu qu'il fonctionne...
Mais je n'en suis qu'aux x = 2 avec i =5; et je viens juste d'ajouter 85
Je pense d'ailleurs que j'aurais besoin d'aide pour généraliser mes formules à partir du moment où j'ai par exemple pour un x les deux formules associées à i = 5 et i =85.
D'ailleurs je remarque que i = 85 quand k est un multiple de 3.
Pour le reste de ta remarque, je n'ai pas d'avis. Disons que ce modèle aura au moins l'intérêt d'étre une "calculatrice de clusters".
Pour un choix de x, voici sa déclinaison sur 200 clusters par exemple. Comme il n'y a plus besoin de bdd, une application peut être codée pour le web. Ce sera une alternative aux sites qui ne font que des suites pour un seul entier à la fois. Voilà un peu d'utilité pour un usage "para-mathématique" dans le genre de calculis.net ou autre.
En poussant un peu plus loin, si j'en ai les capacités, une sorte de table (comme les tables de logarithmes) est envisagable parce que l'on a un ordre k, puis une sous-classe tdv pour classer les clusters. Cet ordre est selon moi l'ordre syracusien qui devrait expliquer pourquoi l'algorithme de Collatz trouve si facilement un chemin vers 1 avec aussi peu d'instructions.
Comparaison n'est pas raison, mais en arithmétique "l'algorithme" n-1 ramène tout entier n à 1 avec un "tdv" = n-1. C'est $\beta$ mais c'est peut-être ce que fait l'algorithme de Collatz quand il remonte un ensemble d'entiers classés dans l'ordre syracusien. Faire ce modèle est pour moi une façon de m'approcher au plus près de ce phénomène, entre autres raisons.
L'ordre syracusien serait peut-être une liste dans ce genre :
k__________x_n_i_tdv
4__________1_0_5_5
7__________1_0_21_7
7__________2_1_5_7
10__________1_0_85_9
10__________2_3_5_9
13__________1_0_341_11
13__________2_5_5_11
16__________1_0_1365_13
16__________2_1_341_13
16__________2_7_5_13
16__________3_6_5_13
18__________2_2_85_12
18__________3_5_5_12
19__________1_0_5461_15
19__________2_3_341_15
19__________2_9_5_15
19__________3_2_341_15
19__________3_8_5_15
19__________4_7_5_15
21__________2_4_85_14
21__________3_3_85_14
21__________3_7_5_14
21__________4_6_5_14
22__________1_0_21845_17
22__________2_11_5_17
22__________2_5_341_17
22__________3_10_5_17
22__________3_4_341_17
22__________4_9_5_17
22__________5_8_5_17 -
L'ordre syracusien, l'ordre des k....
Je prends un i' au hasard, 27 par exemple
On connait presque par coeur l'ordre des i' à i
5, 53, 35, 23, 61, 325, 433, 577, 3077, 2051, 1367, 911, 2429, 1619, 1079, 719, 479, 319, 425, 283, 377, 251, 167, 445, 593, 395, 263, 175, 233, 155, 103, 137, 91, 121, 161, 107, 71, 47, 31, 41, 27
mais qui connait l'ordre des k correspondant à chacune de ces étapes impaires
4, 13, 16, 19, 25, 36, 37, 45, 49, 52, 55, 58, 64, 67, 70, 73, 76, 79, 87, 90, 91, 94, 97, 103, 111, 114, 117, 120, 121, 124, 127, 135, 138, 139, 147, 150, 153, 156, 159, 160, 163
ben tiens ! c'est dans l'ordre parfait de décroissance de 163 à 4
Moi j'en tombe de ma chaise avec des trucs pareils ! J'espère que mon modèle va mettre cela en évidence ! -
Avec les tdv , tu aurais eu le même résultat
")
Et k est la copie quasi conforme du tdv, à un facteur multiplicatif 1.5 près.
Edit : la relation père-fils n'est pas si claire que ça...Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
lourrain mais si le pere a plusieurs freres, je ne vois pas pou pas pourquoi le k de l'un des ces enfants soit supérieur à son kLe 😄 Farceur
-
Je me demande si k ne serait pas plus facile à expliquer en regardant la suite 'compressée' de Syracuse.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin
-
@lourran
Il faut regarder toute la vie avec des yeux d'enfants ... Henri Matisse
Attention tout de même à ne pas introduire nos lecteurs en erreur sur la relation entre k et tdv
la formule du tdv selon k est :
TDV = (4*k+MOD(k;3)*(29-15*MOD(k;3)))/6 (dans Excel)
ou
$\large tdv = \frac{4k+ \text {k mod3}* (29-15*\text {k mod3})}{6} = 7, 9, 11, 13, 15, 17, 19, 21$
Je conseille de toujours revenir à ce lien pour les formules : http://www.les-mathematiques.net/phorum/read.php?43,2058452,2058550#msg-2058550
Le but de k est d'être une suite d'entiers parfaitement régulière et surtout totalement dissociée des suites de Collatz.
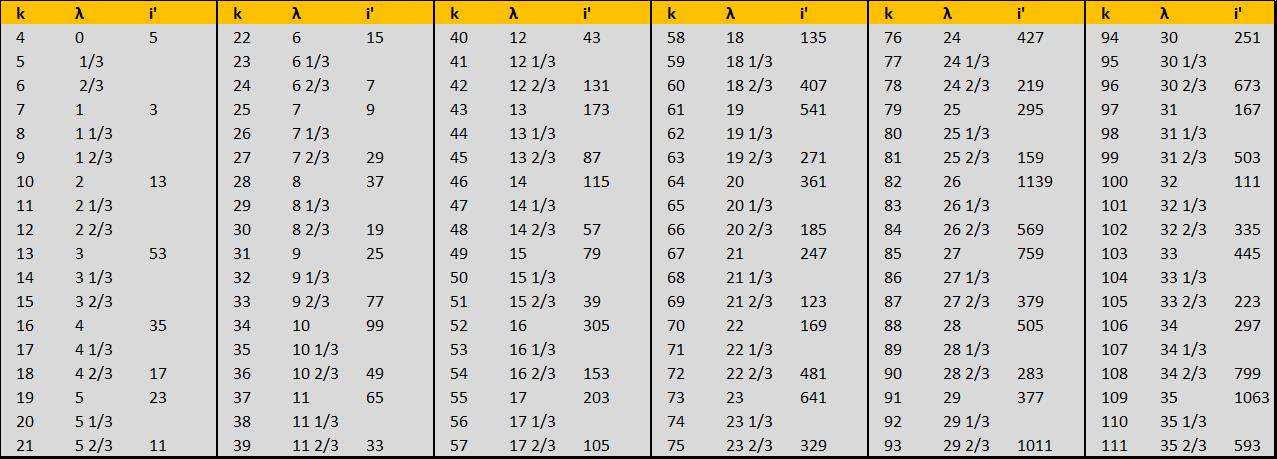
On peut s'arranger pour que $ k=3\lambda +4 $ ; la suite $S(\lambda) = n+1 $ étant l'ordre arithmétique.
De ce fait le modèle va produire des suites de variables de Collatz (i', x, n, i, tdv) dont l'ordre "syracusien" sera toujours relié à l'ordre arithmétique.
https://imagizer.imageshack.com/img922/4417/VpojY7.jpg
On remarque que si je veux avoir une continuité des k, j'aurais des $\lambda$ qui seront des fractions.Deux fractions $\lambda$ séparent une valeur k de k+1. Les fractions en 1/3 n'ont pas de i' car elles renvoient aux étapes paires. Les i' qui apparaissent dans ce tableau sont les minorants d'orbite. On a donc 2 infos sur le classement des i' selon l'ordre syracusien : il dépend de leur valeur k et de l'endroit où ils se trouvent dans la structure : orbite, cluster de l'orbite, rank dans le cluster.
On arrivera bien un jour à montrer que k est bien l'ordre syracusien et que l'algorithme de Collatz ne fait que remonter cet ordre en sens inverse aussi simplement que l'on revient d'un entier n quelconque à 1 en faisant n fois n-1
Un coup d'oeil sur les données de la suite 911 vue sous l'angle de k :
https://imagizer.imageshack.com/img924/1772/yvHbTW.jpg
x revient de 12 à 1 par étape x-1, c'est évidemment parce que nos suites sont des suite d'étapes impaires
n revient de sa valeur de départ à 0 parce que un i (étape impaire finale) a toujours un n = 0
les sauts de n révèlent les différences du nombre d'étapes paires entre 2 i'.
Il serait intéressant d'avoir la formule reliant n à tdv dans une suite (on doit pouvoir l'obtenir en jouant sur les formules existantes)
au niveau des rank de cluster, on voit bien que quelque chose agit pour trouver une position précise. Les rank en 1 sont souvent pour des clusters ayant un seul élément.
Quelle belle structure ! -
tdv est connu, archi connu. Une formule tdv= blabla(k) n'a donc pas beaucoup d'intérêt.
Si tu veux une formule utile, ce serait plutôt une formule du type k=blabla(tdv) , mais ça, ce n'est pas possible puisque pour un même tdv, on n'a pas toujours le même k ( quand tdv=20, k=23 ou 30 selon les nombres)
Donc peut-être une formule k=blabla(tdv,x) ?Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
Dégager des collections de i' depuis une simple suite arithmétique S(k) n'est déjà pas si mal et c'est la mission de mon modèle d'y parvenir.
Pour les formules, si tu regardes bien le tableau 2 du message http://www.les-mathematiques.net/phorum/read.php?43,2058452,2058938#msg-2058938
je parierai plus sur une formule k pour un couple (x, i), cherchant tous les couples (n, tdv) pour lister tous les $i' \in\text{x_n_i_tdv}$
$\large \operatorname{fonction}_k^{i,x}= \text{liste i'} \in\text{x_n_i_tdv}$
Donc le modèle pourrait très bien avoir comme question : donne-moi les i' des clusters pour x = 12 et i = 5. Dans la bdd il suffise que je filtre ces deux valeurs et j'ai ces i' dans la limite de cette bdd. Le modèle pourrait passer outre cette limitation parce qu'il a une méthode pour le faire. J'y suis arrivé à ce jour pour x=2 et i=5
https://imagizer.imageshack.com/img924/8141/T6G8fK.jpg -
Si tu veux continuer à jouer avec ce nombre k il faut comprendre ce qu'il représente.
Parce que là, on part dans l'ésotérisme.
Pour un nombre i', comment calcules-tu k ?
Je donnais il y a quelque temps k = 1.5*tdv quand tdv est pair, et k=1.5*tdv-3.5 quand tdv est impair, est-ce correct ?
C'est valable sur les nombres du dernier tableau, mais tu filtres certains nombres qui ont des profils très particuliers. Donc aucune certitude que ça se généralise à tous les nombres.
Dans ta formule, quand k=23 ou quand k=30 , ça donne tdv=20. Et ma formule dit ; quand tdv=20, k=30.
En fait, peut-être qu'il n'y a aucun nombre avec k=23 ? Et dans ce cas, les 2 formules pourraient être valides ?
En dernier recours, donne un tableau avec tous les i' entre 100 et 1000, et les valeurs x,n,i,tdv et k pour ces nombres (les PAIRS et les impairs).Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
j'ai compris ce dont tu as besoin !
Bien sûr que k ne sort pas de nulle part ! C'est un nombre qui doit obéir à deux conditions :
1) être une suite arithmétique la plus simpe possible
2) être capable de s'associer avec toutes les lignes de la bdd (ligne contenant les i', x, n, i tdv ....)
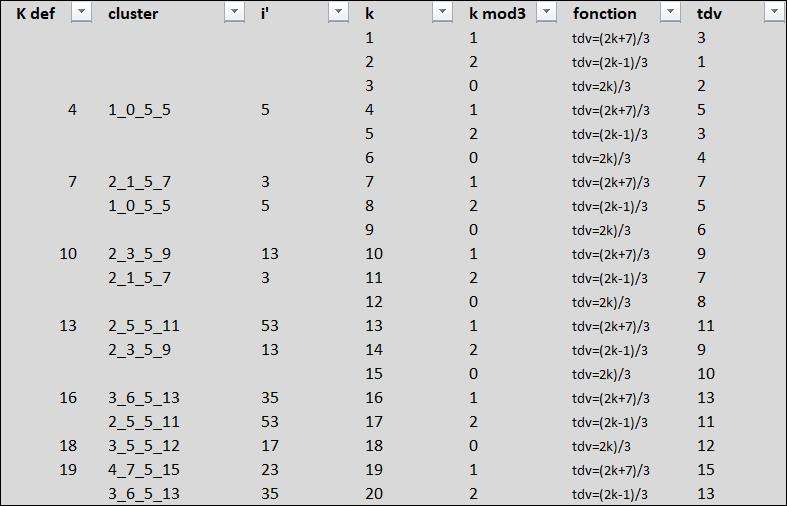
Donc voilà comment je fais ( transparence à 100% !)
1) D'abord j'écris une suite de k dans l'ordre arithmétique le plus simple : 1,2, 3, 4, 5, 6, 7, 8, 9,....
je mets cette liste en colonne D que j'intitule "k"
En colonne E que je nomme "k mod 3", je calcule =MOD(k;3)
En colonne F je répète toutes les 3 lignes le texte "tdv=(2k+7)/3" , "tdv=(2k-1)/3", "tdv=(2k)/3" (ça sert de pense-bête)
En colonne G, nommée "tdv" dans le même ordre de 3 lignes, ces 3 formules =(2*D5+7)/3, =(2*D6-1)/3, =2*D7/3
En colonne B que je nomme cluster je calcule =SIERREUR(INDEX(DATA_cluster;EQUIV(tdv;DATA_tdv;0););"")
Cette manip va chercher pour les tdv de la colonne G leur équivalent cluster dans la base de données
En colonne C que je nomme i', je calcule =SI(B5<>"";INDEX(DATA_iprim;EQUIV(B5;DATA_cluster;0););"")
Cette manip va chercher pour les clusters de la colonne B leur équivalent i dans la base de données
Enfin en colonne A que je nomme Kdef je calcule =SI(B5<>"";SI(NB.SI(B$5:B5;B5)=1;D5;"");"")
Cette manip va virer les doublons de clusters et ne choisir que le premier qui apparait
Donc kdef est une suite d'entiers "la plus simple possible" tout en étant profondémment ancrée dans la bdd
Je complète tout ça jusqu'à K = 750
et je nomme les plages de cet onglet FORMULEk_{nom de la colonne}
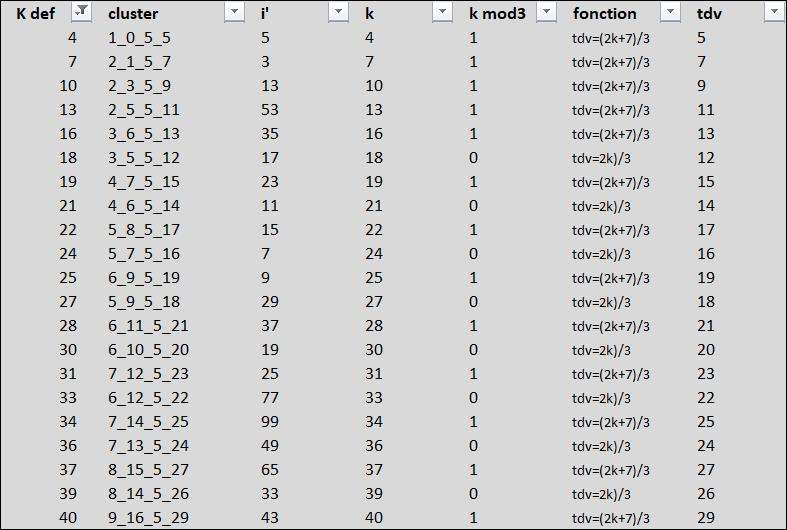
2) Dans ma bdd (onglet DATA, je crée une colonne que je nomme "k" où je calcule
INDEX(FORMULEK_kdef;EQUIV(tdv;FORMULEk_tdv;0);)
Là on va chercher les tdv de la bdd et les associer au Kdef. J'ai donc maintenant une valeur k pour mes 100.000 i'
Note : je m'aperçois que si ces manips ne sont pas décrites en détail, c'est incompréhensible vu de l'extérieur. Donc lourran je te remercie de me forcer la main parce que tout cette documentation sera faite !
En visuel cela donne ça
1) avec tous les k 1,2, 3, 4, 5, 6, 7, 8, 9,....
https://imagizer.imageshack.com/img923/1942/pQ9gjN.jpg
2) puis en filtrant les k inutiles
https://imagizer.imageshack.com/img924/8430/Y13oy2.jpg
Et c'est là que la suite k, 7, 10, 13, 16.... apparait. Une petite suite de raison 3 à partir de 7 (seuls les formes 2k/3 et (2k+7)/3 sont les bonnes)
Il faut aussi savoir que cette liste affiche les i' minorants d'orbite dans l'ordre des k
C'est déjà une grosse étape pour la base de mon modçle.
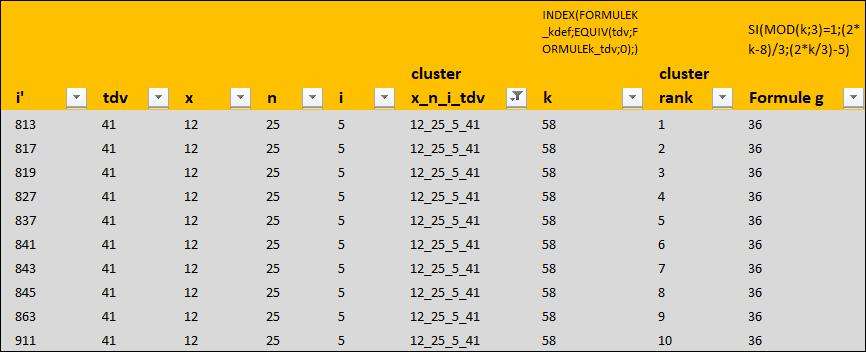
Dans la bdd ce qui se passe est un peu plus complexe, parce que cette fois tous les i' on leur valeur k.
pour k = 58, on tombe sur le cluster 12_25_5_41 lieu de résidence du célèbre 911
https://imagizer.imageshack.com/img924/1917/G1UaAx.jpg
Donc par cluster un k, un tdv et un g pour ne pas l'oublier
C'est ma méthode. Elle marche et je construis le modèle sur ces fondations.
Pour ta demande d'avoir une liste avec les pairs et les impairs, c'est jouable mais je ne l'ai pas car je suis en plein dans ma bdd de i'
Essaie de voir ce que tu peux déjà faire avec ces informations -
Apparement, la formule que je donnais au début semble confirmée :
si tdv est pair, alors k=1.5*tdv sinon k=1.5*tdv-3.5
Ou dans excel : k = 1.5*tdv - 3.5*mod(tdv,2)
Cette formule ne donne jamais k=11, 14, 17, 20, 23 ... mais de ton coté non plus, tu n'as jamais de nombre avec k=11, 14, 17, 20, 23 ...
Dans une suite comme celle partant de 27 , 41 .... etc
Entre 2 impairs consécutifs, on a tdv qui vaut au moins 2 (on n'a jamais 2 impairs consécutifs dans un chemin de Syracuse)
Si l'écart entre 2 impairs consécutifs est de 2, la formule en question va nous donner un écart de 3. (1.5tdv0 - 1.5 tdv1)
Et si l'écart entre 2 impairs consécutifs est de 3, la formule ci-dessus donnera soit un écart de 1, soit un écart de 8 ...
Mais dans les 3 cas, quand tdv augmente, k augmente.
k ne peut pas diminuer quand tdv augmente.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
J'ai l'impression de parler à un mur.
Trouver tdv à partir de k, on s'en moque (en tout cas, je m'en moque).
Si k a un vague intérêt, on doit pouvoir déterminer k à partir de i'.
Donc, on veut une formule k= ...
Je propose depuis un certain temps k=1.5*tdv quand tdv est pair, et k=1.5*tdv -3.5 quand tdv est impair. As-tu dans tes différents fichiers des cas où cette formule ne marche pas ?
Cette formule est-elle bonne ou pas ?Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
LOURRAN a écrit:k=1.5*tdv quand tdv est pair, et k=1.5*tdv -3.5
non c'est faux
en fait la bonne formule est un peu plus tordue
\begin{array}{r c l}
k mod3=1 & tdv = & \frac{2}{3}*k+\frac{7}{3}\\
k mod3=0 & tdv = & \frac{2}{3}*k
\end{array}
Dans Excel : tdv =SI(MOD(k;3)=1;(2/3)*k+7/3;(2/3)*k)
Par rapport à ta reflexion, je suis plus un chasseur de i' que de tdv
Le plus diificile pour le modèle est bien d'associer un i' à un k
Maisi Il faut passer par le tdv pour trouver d'autres variables, voir ici
http://www.les-mathematiques.net/phorum/read.php?43,2058452,2058550#msg-2058550
Pour le tdv cette formule marche très bien :
$\large tdv = \frac{4k+ \text {k mod3}* (29-15*\text {k mod3})}{6} $ -
Grrrrr
Tu tiens vraiment à mettre k en 'principal' , et déduire tdv à partir de k.
En inversant la formule que tu donnes, on a bien celle que je donnais depuis plusieurs jours. k = 1.5*tdv si tdv est pair, et k=1.5*tdv - 3.5 si tdv est impair.
Conclusion de tout ça (ta formule, ou la mienne) ; k ou tdv , c'est pareil.
Si tu travailles avec tous les i' pairs ou impairs. Il y a des inversions. Soit, peu importe.
Si tu travailles avec uniquement les i' impairs, k ou tdv, c'est kif-kif.
Tu renumérotes les tdv, tu décales certaines valeurs, mais tu travailles avec une copie de tdv.
Et tu t'étonnes : quand tdv augmente, la copie de tdv augmente aussi...Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
il se trouve que le modèle se fabrique bien avec k, et une méthode qui marche ça me va
n'oublie pas que de mon côté je ne fais pas de maths en priorité. Je veux mener ce modèle à son terme.
j'ai déjà dit dans des messags antérieurs qu'il y avait bcp de ''tdv-like'' (y ou z en font partie) : je connais bien cet aspect des données.
Mais k, tout tdv-like qu'il est, est surtout le point d'entrée du modèle, c'est la liaison entre la logique de l'arithmétique où toutes les opérations sont validées par son ordre fondateur, et une sorte d'arithmétique "transformée" avec un autre ordre et une seule opération possible : la remontada vers le 1 avec l'algorithme. Tu arrives à comprendre ce point de vue ?
Je dis sérieusement que l'algorithme de Collatz équivaut à faire (en arithmétique "normale") n-1 à partir de n'importe quel entier n si on veut revenir à 1 en n-1 opérations. ça a l'air un peu débile, mais c'est une bonne image parce que si l'algorithme de Collatz remonte si bien vers 1 lui aussi, cela veut dire que cette opération est le "n-1" dans l'ordre de Collatz. Sauf qu'il y a une énorme différence parce que n-1 quand il est revenu à 1, on peut revenir au point de départ en faisant n fois n+1. Et ça l'algorithme ne sait pas le faire. Là on va essayer de faire des listes de g, mais ce n'est plus l'algoritme si simple et si efficace. J'aimerais beaucoup que toi ou d'autres profitent de ce fil pour donner leur opinion sur ce sujet précis. -
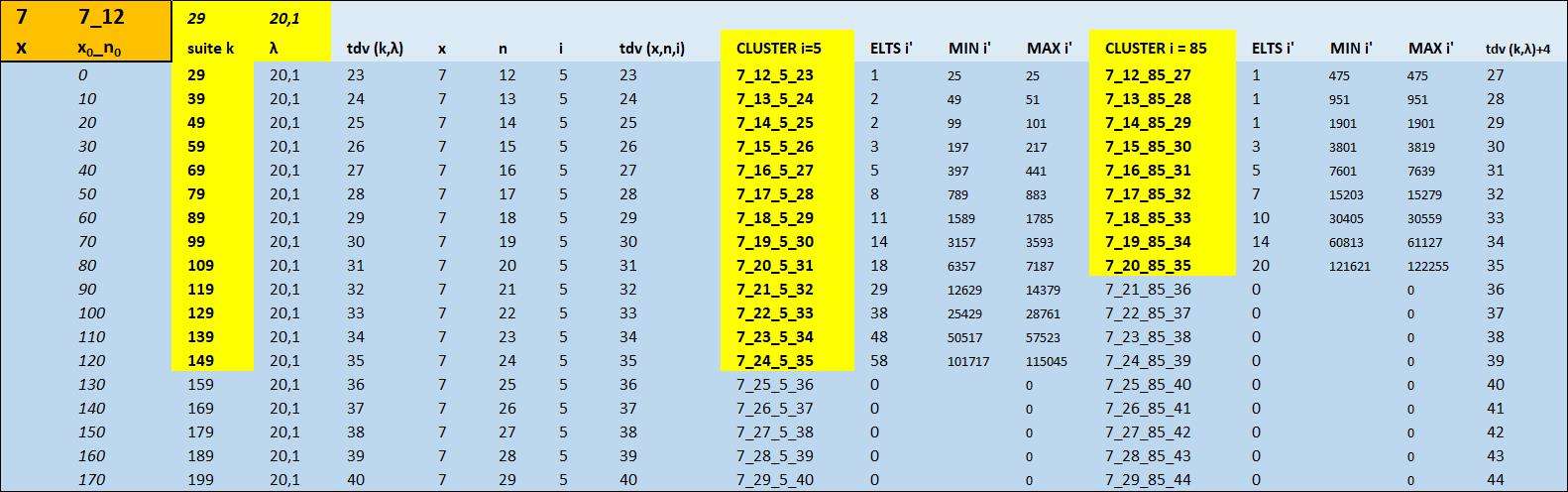
Le modèle se poursuit avec les nouvelles formules sont pour $x=2 \text{ avec } i = 85$
C'est le principe du modèle que de ne prendre en source qu'une suite arithmétique tout simple qui n'a en soi aucun rapport avec les suites de Collatz.
Cela a été fait à la demande de Berkouk d'utiliser $\lambda$ pour générer $k$ en faisant que la suite $\lambda$ soit vraiment une suite en n+1
Disons que j'aime bien cette solution parce que j'ai la petite transformation de $\lambda$ en $k$ et du coup on a la raison de la suite $k$
Donc pour $x=2 \text{ avec } i = 85 : \lambda \text{ part de 6 et } 3\lambda = k$
Voici les données telles qu'elles sont affichées sur Excel
https://imagizer.imageshack.com/img922/362/ujFQWC.jpg
et les formules utilisées :
$\lambda $ de 6 à 27 : rien est trouvé avant 6 et on sort des possibilités d'Excel après 27
$k = 3\lambda$
$n = \frac{2k}{3}-10$
$i' =\frac{4}{3}*2^{(2*k/3-12)}*85-\frac{1}{3}$
$tdv = \frac{4k+ \text {k mod3}* (29-15*\text {k mod3})}{6}$
$x =\lfloor LOG_6{2^{tdv/i'}} \rceil $
$i = \frac{2^{tdv-x-n}-1}{3} $
Pour les deux dernières formules, rien n'empêche de n'utiliser que le k en réinjectant les formules précédentes de tdv, i', (et x dans la dernière)
cluster : concaténation (x,n,i, tdv)
Là où c'est toujours agréable, c'est d'aller vérifier un des i' dans https://repl.it/repls/EthicalTangibleLocations#main.py
x_n_i_tdv : 2_44_85_54
498445271258453
coïncide parfaitement avec la ligne k = 81 -
Bonne nouvelle, Berkouk derait être beaucoup plus 'challenging' que moi.
Personnellement, je n'ai jamais cru beaucoup en nos capacités à démontrer quoi que ce soit.
Par contre, avec Berkouk comme coach, ça devrait mieux se passer. Lui va pouvoir te tirer vers le haut, te motiver.
Ensemble, vous allez pouvoir bâtir 5 ou même 10 démonstrations différentes de la conjecture.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
@lourran
1) personne de démontre rien sur ce fil qui est consacré à la conception d'un modèle dont le but est d'associer une série d'entiers k à la totalité de la bdd actuelle, voire plus en prédisant des i' ou des clusters bien au-délà des capacités de calcul d'Excel.
2 Le modèle montrera (un modèle c'est fait pour montrer, pas démontrer) qu'on peut au final mettre en valeur un ordre des suites de Syracuse en classant l'ensemble de la bdd dans l'ordre du k. Je peux faire ce classement aujoud'hui puisque j'ai un k par i', mais ça ne me donnera l'explication de cette association. Il faut donc trouver par valeur de x et de i les bonnes formules permettant de calculer les variables de l'ensemble du cluster.
3) Le petit bout d'information qui fait défaut à ce jour sur les suites de Collatz, est bien caché dans les paramètres des formules qui tranforment un k en i', x, n, i tdv. Lorsque ces paramètres seront exposés, il y a de bonnes chances qu'ils soient reliés par d'autres formules plus générales.
4) c'est bcp de travail de faire cela. Personne ne m'oblige à rien, mais si je voulais juste blablater sur un forum, j'aurais pris un sujet demandant moins d'effort. -
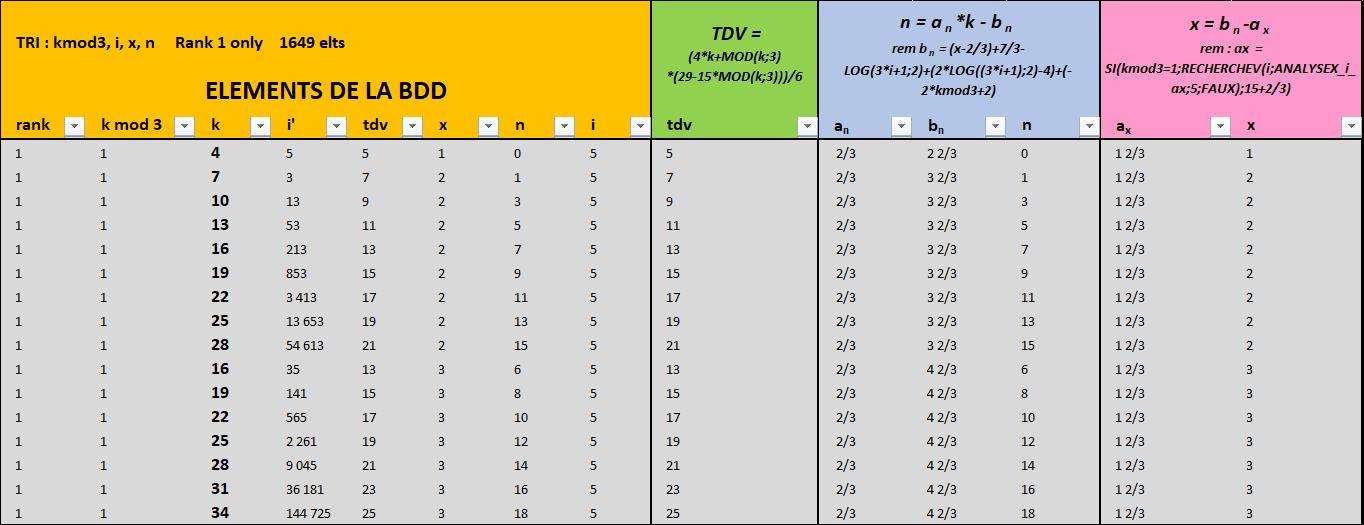
La modèle fait de bon progrès avec la modélisation désormais complète de tdv et n par rapport à k pour les "premiers de clusters" (minorants de leurs clusters) de la bdd.
Je rappelle que le principe de ce modèle est de pouvoir exprimer la totalité des variables des suites de Collatz uniquement en fonction d'une suite arithmétique ''banale" S(k).
La première étape de la construction du modèle est de trouver pour les i' minorants de cluster une formule ayant k comme variable unique pour chaque variable de Collatz.
Pour info, il y a 1649 clusters dans la bdd pour les i' de 3 à 200.0001. Donc cette première étape concerne les 1649 i' minorants de ces clusters.
La deuxième étape sera consacrée à trouver la relation k, i' dans un même cluster, sachant que nous aurons les paramètres x, n, i, tdv de ce cluster et que nous savons calculer le minorant et le majorant d'un cluster. Cette étape ne semble donc pas impossible à franchir.
Pour le tdv c'est simple :
$\large tdv = \frac{4k+ \text {k mod3}* (29-15*\text {k mod3})}{6}$
Equivalent Excel : tdv = (4*k+MOD(k;3)*(29-15*MOD(k;3)))/6
Cette fonction à variable unique k fonctionne dans tous les ''k'' ;-)
donc quelque soit x, n, i, et i'
Pour les n, cela a été plus difficile
$\large n = a_{n}*k - b_{n}$
Le paramètre $ a_{n}$ est le même pour les 1649 cas.
C'st le paramètre $b_{n}$ qui est complexe.
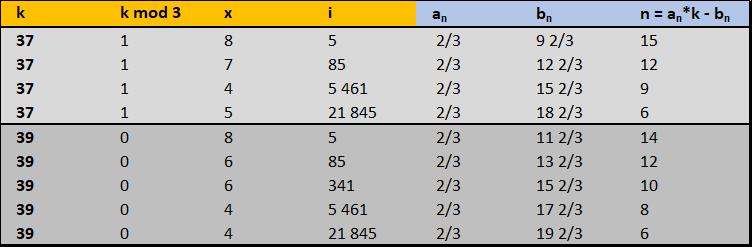
En effet après analyse de la bdd, j'ai pu observer que
$\large b_{n} = (x- \frac{2}{3}) +\frac{7}{3} -log_2{(3i+1)}+(2log_2{(3i+1)}-4)+(-2\text{kmod3}+2)$
Equivalent excel : $b_{n}$ = (x-2/3)+7/3-LOG(3*i+1;2)+(2*LOG((3*i+1);2)-4)+(-2*kmod3+2)
La formule n'est pas très élégante mais elle ne sert qu'à qu'à montrer que $b_{n}$ évolue selon i, x, et k mod3
On voit clairement ce qu'il se passe pour k = 37 et 39 avec les combinaisons de k mod3, x et i
https://imagizer.imageshack.com/img923/9683/hZirW3.jpg
On voit que les $b_{n}$ évoluent de manière linéaire en fonction de i et kmod3
Le plus simple est de penser que chaque k à un kmod3 en 0 ou 1 et une série de i (5,21,85,341...) qui se traduiron en $b_{n}$ -
Le modèle est désormais étendu à tdv, n et x.
https://imagizer.imageshack.com/img922/5521/2QAMkE.jpg
Les colonnes sous les cellules orange sont le rappel de la bdd
Je rappelle que nous sommes dans la bdd réduite aux minorants de clusters (1649 i' sur 100.000)
On voit le calcul du tdv sous cellules vertes : il ne dépend que de $k$
Puis le calcul de $n$ sous les cellules vertes
Là on associe dans la formule $k$ à deux paramètres $\large n = a_{n}*k - b_{n}$
$a_{n}$ et $b_{n}$ sont des fractions dont le dénominateur est toujours 3 : ces valeurs viennent d'une analyse de la bdd.
Il reste à trouver une méthode pour les construire de manière indépendante de la bdd, mais c'est déjà une bonne base de les connaitre.
C'est le même principe avec la fourmule :$\large x = b_{n}-a_{x}$
On réutilise $b_{n}$ et $a_{x}$ est aussi une valeur venant d'une analyse de la bdd.
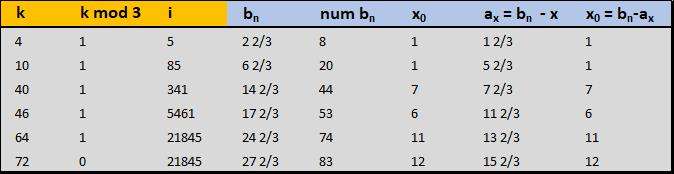
Les suites $a_{n}$, $b_{n}$ et $a_{x}$ inspireront peut-être des gens plus doués que moi pour trouver le principe de leur construction. Elles sont liées à i (5, 85, 341...) et kmod3 (1 ou 0) comme on peut le voir sur ce tableau :
https://imagizer.imageshack.com/img922/5421/53ZIor.jpg
Donc merci à tous ceux qui suivent ce fil. Vos avis sont les bienvenus, et quelques encouragements ne font pas de mal non plus
Si vous jetez un coup d'oeil au pdf joint, vous verrez tous les détails du modèle pour les 1649 i' minorants de clusters -
J'ai répéré quelques soucis dans le dernier modèle publié
mode debug en cours ! -
Le "mod debub" du modèle a abouti a une révision intégrale de la manière de définir et d'encoder $\large k$ !
Une façon de dire que j'ai à peu près tout recommencé depuis le début.
Faire un prototype expose à ce genre de situations. On a parfois un dilemme assez simple entre tenter à tout prix de rustiner les erreurs en espérant que ça tiendra, ou de faire table rase et de recommencer from scratch. Je penche souvent pour le choix de la table rase si mon intuition me pousse vraiment à le faire, et si c'est matériellement possible de le faire. Dans la vie pro, il y a souvent des problèmes de délai et il faut souvent se contenter de réparer faute de temps.
Mais là je ne suis pas dans la vie pro, je suis sur un projet perso et je n'ai aucune envie de rester sur un échec au vu du temps passé.
En même temps, ce nouvel encodage du $\large k$ va pratiquement me donner d'un coup toutes les formules. Donc j'arriverai à la fin de la première étape dès que la suite k sera finie.
Je rappelle que le but du jeu est vraiment d'avoir en entrée du modèle une simple suite d'entiers k et de disposer en sortie des variables des suites de Collatz : i', tdv, x, n et i. Sans évidemment de recours à la bdd, ou à une utilisation de l'algorithme.
Est-ce des maths ou pas des maths? Est-ce utile à une démonstration de la conjecture? J'ai eu une grosse opposition sur ce forum pour dire que non, de manière parfois un peu trop systématique. Vous en êtes peut-être maintenant convaincus. Mais j'ai quand même eu quelques encouragements, peut-être de gens qui ont l'intuition que cela peut mener à quelque chose.
Il y a des exemples dans les mathématiques où une longue période de travail pratique est nécessaire avant de passer à l'étude mathématique proprement dite. Je pense évidemment à l'histoire des statistiques qui est résumée ici https://fr.wikipedia.org/wiki/Histoire_des_statistiques#:~:text=On attribue à l'histoire,, de l'allemand Staatskunde.
Sans vouloir trop pousser le bouchon, mon modèle va (peut-être) améliorer les connaissances "statistiques" des données de Collatz. Je ne pense pas que l'argument critique que tout soit déjà connu sur ces suites soit valide. Si toute l'information avait été vraiment remontée, une démonstration existerait. Les suites de Collatz demandent à mon sens d'être mieux observées, et pas uniquement en calculant des nombres longs comme des murs.
Pour conclure, je peux vous dire deux choses. Concevoir ce modèle est une des choses les plus compliquées que j'aie eues à faire à ce jour. J'ai quand même à mon actif sur Excel un modèle d'analyse de scénarios de films d'animation 3D qui peut sortir automatiquement un séquencier "timé" (durée de chaque séquence, estimation du nombre de plans), avec tout le détail personnage par personnage, des documents de breakdown et de bidding toujours tirés de l'analyse de scénarios qui permettent de faire avec précision des devis de plusieurs millions d'euros, des tas d'outils d'analyse de données de production de ce type de films qui permettent de faire des projections à plusieurs semaines de la situation de production à venir, et pour le fun, un solveur de sudoku qui arrive au niveau de résolution des grilles diaboliques.
Donc la complexité de l'analyse des données et de la conception d'outils pour le faire, je connais un peu quand même. Alors je ne sais pas si c'est des maths ou pas, mais ce n'est pas des recettes de cuisine non plus. Donc si je parviens à finaliser ce modèle, ce sera tout de même le travail d'un spécialiste.
Donc si l'idée de certains est de me faire endosser de force le costume de "l'amateur pensant avoir démontré..." , merci de vous souvenir de ce que je vous ai dit aujourd'hui. Je ne dis pas ça pour me faire mousser, mais comprenez tout de même que j'avais besoin de cette mise au point pour briser certains a-priori.
J'espère donc vous montrer la nouvelle version du modèle d'ici quelques jours, et surtout de trouver les bons mots et les bonnes illutrations pour qu'il soit compréhensible. Je fais tout ce que je peux pour réduire au maximum le ''lost in translation" parce que je ne suis pas spécialisé dans la rédaction d'énoncés mathématiques. Je me suis mis au LaTeX depuis que je tiens ce fil parce que je voyais bien que les formules Excel ne passaient pas bien l'information souhaitée.
J'ai besoin de vos retours pour avancer. Je pense que la conception de ce modèle, et son but, peut espérer échapper à une critique caricaturale. -
Je vous présente la version ''béta" de mon modèle des suites de Syracuse ou Collatz.
En résumé, ce modèle se définit en ''entrée/sortie'' par :
Entrée : une suite $k$ ayant un premier terme $k_{0}$, de raison $r$ et $k_{n}$ termes
Sortie : des suites de variables de Collatz : i', tdv, x, n, i, clusters, minorant et majorant de clusters, etc....
Le calcul des données sortantes doit évidemment n'avoir aucun recours à la bdd, ni à une utilisation de l'algorithme; la bdd ne servant qu'à vérifier la justesse de ces données.
Ce qui a énormément évolué par rapport aux premières versions, est la manière de définir ce $k$, de trouver comment je pouvais le lier le plus profondémment possible avec les suites de Syracuse. Il fallait pour cela concevoir une formule particulière du tdv selon k :
$\large TDV = 0.1k+\lambda = x+n+log_2{(3i+1)} $
L'autre évolution majeure est d'utiliser un couple $\large x, n$ (x étapes impaires et n paires) pour générer la suite $k$ qui lui est associée.
Il y a deux niveaux dans le modèle :
niveau ''encodage" : analyse de la bdd pour chaque couple x,n de manière à trouver sa suite $k$ et la valeur $\lambda$ qui lui est associée.
niveau ''décodage" : en appelant un couple $\large x, n$ , une suite $k$ est génerée à laquelle s'associe un ensemble de clusters possédant tous le même $\lambda$ et le même $x$. Ces clusters se déclinent par familles de i (5, 85...) et suites de n de raison 1.
Je travaille ici que ce travail est purement technique. Le modèle est l'aboutissement logique d'une analyse de données. Sans a-priori de départ, et sans chercher à démontrer quoi que ce soit, l'analyse de données pure et dure (ranger, classer, trier, supprimer les redondances, établir des corrélations) fait sortir de l'information des données comme on fait sortir le jus d'un citron en le pressant. Le modèle ne fait que mettre en pratique cette information : une ''query" est posée en entrée et le modèle propose une réponse.
Au début de sa conception, le modèle se contente d'une simple lecture de la bdd et par filtrage donne une réponse à la réquète. En fin de conception, le modèle devient indépendant de la bdd avec une capacité prédictive : il va donner des résultats pour des données qui n'ont jamais été calculées. La version béta actuelle est à mi-chemin entre ces deux étapes. Elle commence à gagner en indépendance mais il lui manque encore quelques formules pour l'être tout à fait. Il est évidemment impossible de sauter cette étape intermédiaire.
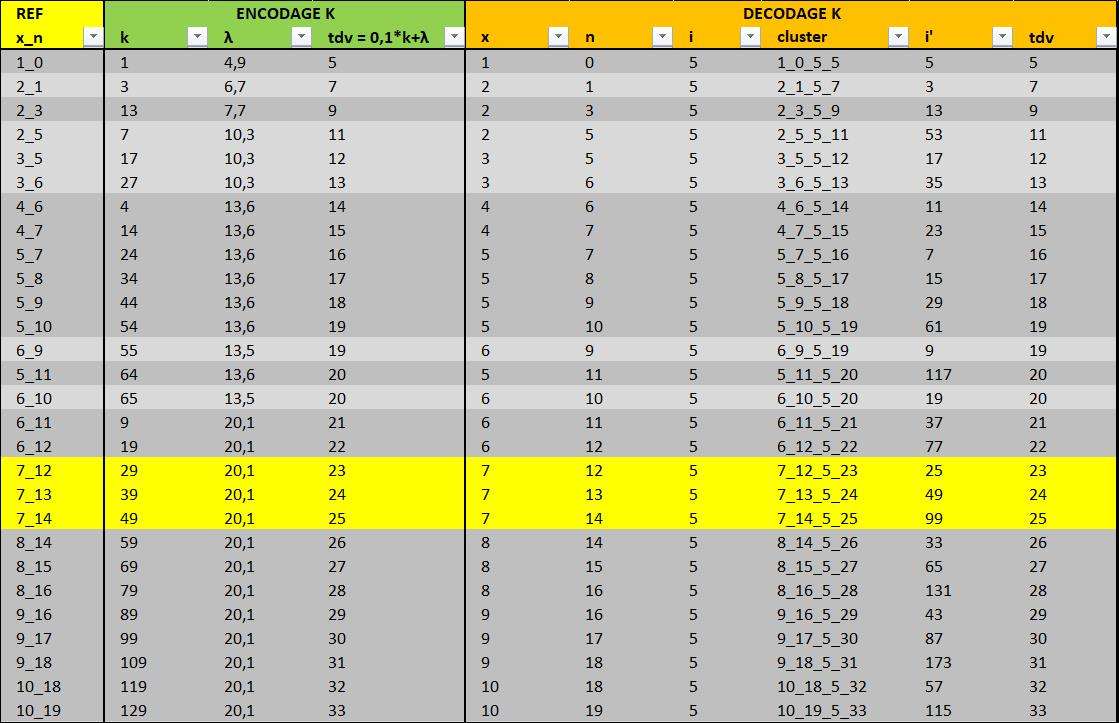
Voyons donc le niveau "encodage''
https://imagizer.imageshack.com/img923/8171/zfFxbe.jpg
C'est en fait une compression de la bdd par couple x_n. La valeur de $\lambda$ s'obtient si $tdv = 0,1*k+\lambda = x+n+log_2{(3i+1})$. On remarquera que la suite $k$ pour un même $\lambda$ est de raison 10. Trouver le $k_{0}$ de ces suites nécessite bcp de manips avec les données. Une fois que l'on a la suite $k$ complète pour un couple x_n, il suffit de lister les variables des clusters correspondants.
Et donc le modèle en sa version ''béta"
https://imagizer.imageshack.com/img924/3088/2Dt6KM.jpg
Le ''query'' de cet exemple est le couple x_n = 7_12.
$k_{0} = 29 $ et la suite de raison 10 et de 13 termes va jusqu'a 149.
$\lambda = 20.1$ et la suite n de raison 1 part de $n_{0}=12$ , le 13ème terme étant 24.
On constate bien l'égalité des deux calculs du tdv : $ TDV = 0.1k+\lambda = x+n+log_2{(3i+1}) $
Le modèle pourrait produire tous les clusters par valeur de i. Pour simplifier à ce stade, seuls i = 5 et i =85 sont proposés. Pour ces clusters ayant tous x=7 et le même $\lambda = 20.1$ on affiche à leur droite les i' (minorant, majorant, nbr elts) par recherche dans la bdd.
Noter que si i <> 5, le calcul du tdv est $ TDV = 0.1k+\lambda +log_2{(3i+1)}-4 $
A ce stade, cette version ''béta" scanne 94% de la bdd.
OBJECTIFS pour les prochaines versions
1) Compléter les valeurs de $\lambda$ manquantes (9 sur 141)
2) Formule pour calculer $k_{0}$ et le nombre de termes de la suite $k$
3) Formule pour calculer $n_{0}$ depuis $x_{0}$
4) Formule pour calculer $\lambda$
5) Formule pour les i' minorant et majorant de clusters (on a déjà des formules de bornage de ces i')
Il y a bcp de formules dans ce fil de discussion (et dans le précédent) qui pourrait aider en ce sens. Mais si vous avez une idée, merci de la partager ! -
Je vous présente la version ''béta 2" de mon modèle des suites de Syracuse ou Collatz.
Comme son nom l'indique elle est l'évolution de celle de mon message précédent : http://www.les-mathematiques.net/phorum/read.php?43,2058452,2061126#msg-2061126
A tenir le journal du développement de ce modèle, je prend le risque de montrer les aléas de ce genre de recherches. Lourran me dirait volontiers que je ''tourne en rond'', mais tout en admettant que je n'avance pas très droit, je dirais plutôt que je ''tire des bords'' (navigation en zigzag provoqué par un fort vent de face). Ce qui est tout de même une façon d'avancer.
Cette histoire de suite de Syracuse est surement un des jeux les plus sophistiqués jamais inventés, où l'on part d'un truc simplissime pour arriver à une complexité quasi-absolue : indécidabilité, question quasi-philosophique de l'existence/non-existence de N2 (http://www.les-mathematiques.net/phorum/read.php?43,1993402,2058176#msg-2058176)
Moi je me cramponne à faire un modèle dont l'objectif est de sortir la dernière goutte d'information de N1 pour rester dans les termes de Lourran.
Ce modèle "béta 2" est basé sur ces éléments suivants :
1) la formule "tdv", toujours au centre du modèle, est : $\large tdv = k+\lambda$
2) Le principe est toujours d'associer une suite arithmétique k aux variables de Collatz
donc autant choisir la plus simple de toute : k est la suite des entiers naturels (suite arithmétique de premier terme 1 et de raison 1)
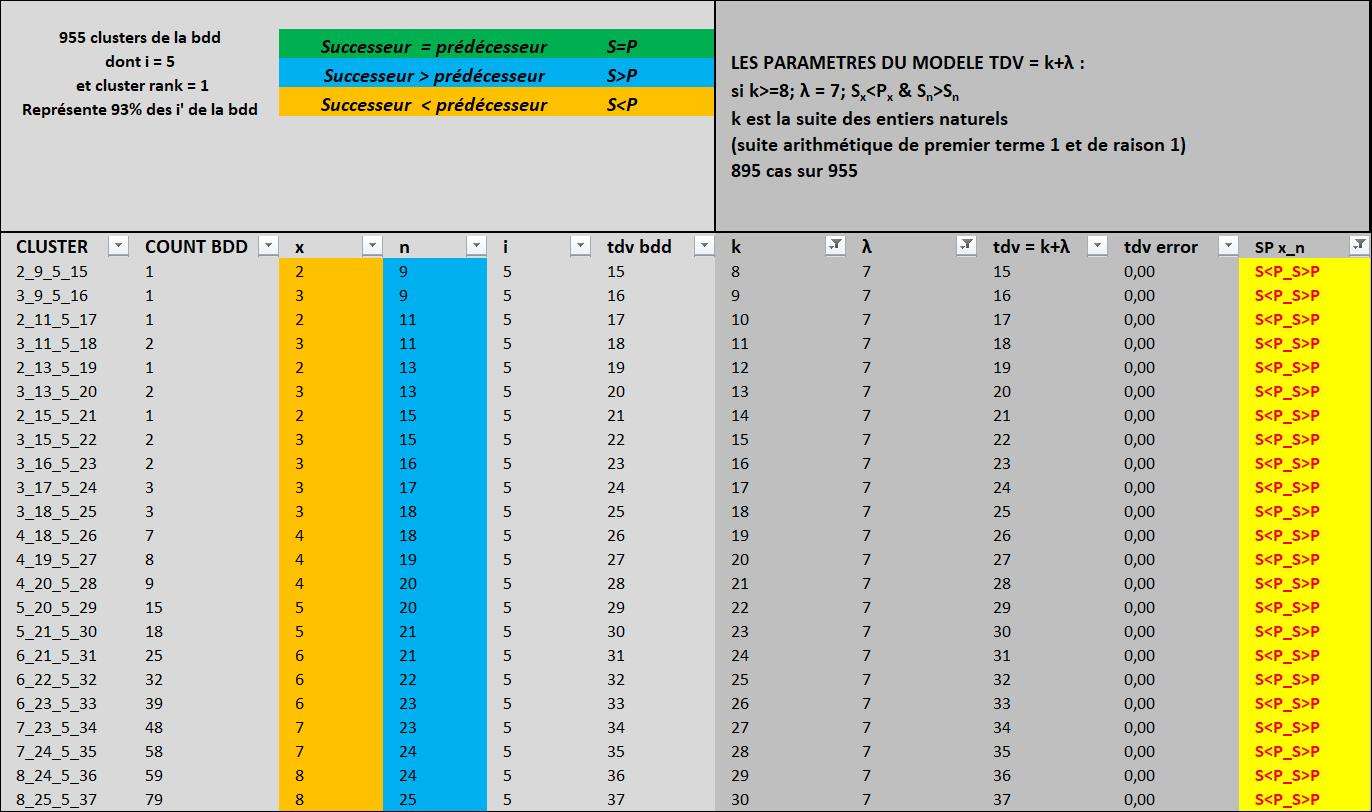
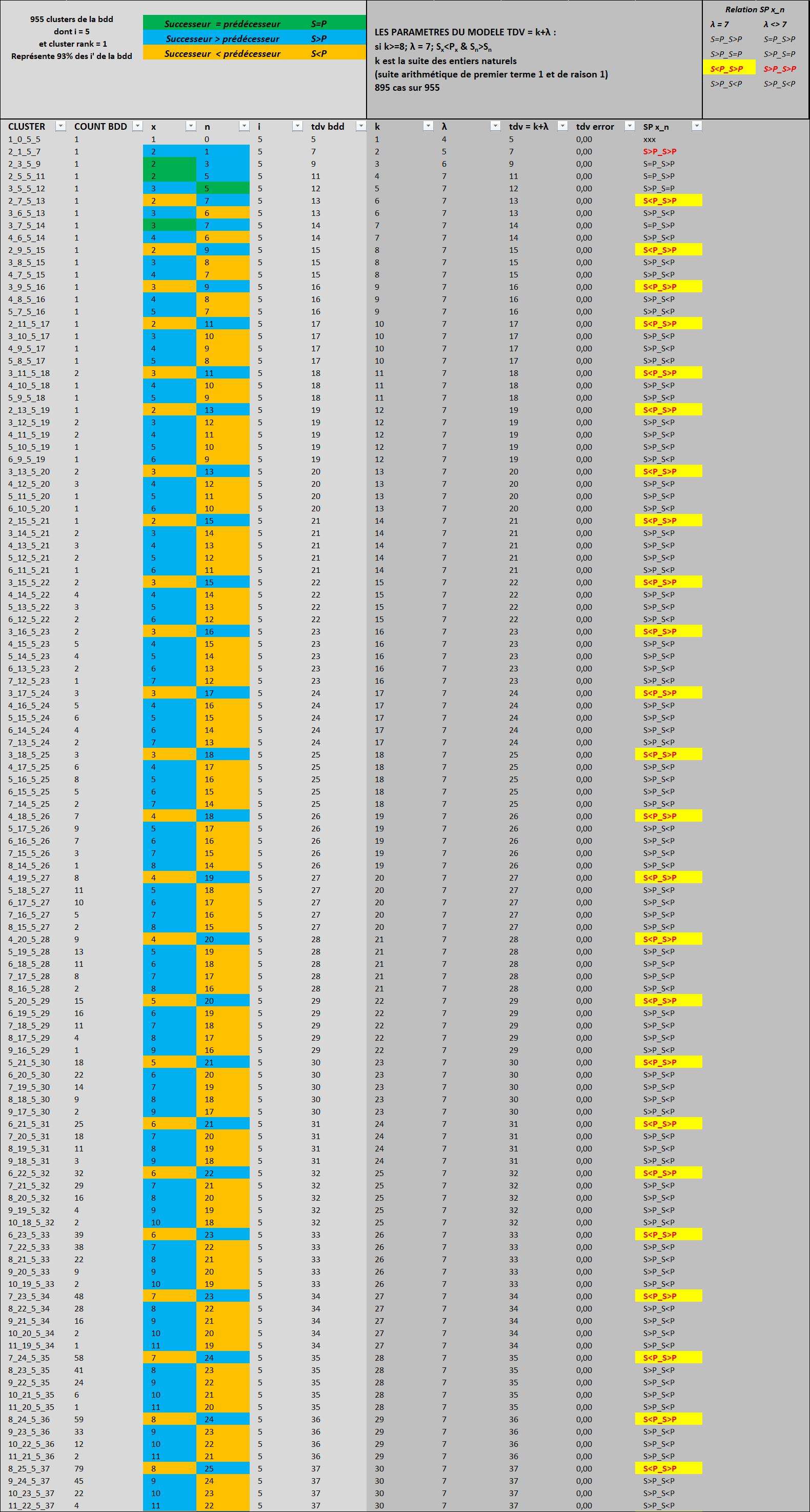
3) Dans cette version, il y a un gros focus sur les relations prédécesseur/successeur de x et n dans l'ordre que vont prendre ces variables si on classe la bdd réduite aux i = 5 dans l'ordre croissant des tdv (donc par orbite) puis selon l'ordre de x et n.
4) Dans cet ensemble de 995 clusters représentant 93% de la bdd complète,
en considérant S le successeur et P le prédécesseur de x ou de n,
que l'on écrit ''relation prédécesseur, successeur de x _ relation prédécesseur, successeur de n''
il existe 5 cas possibles :
S=P_S>P $\forall\lambda$
S>P_S=P $\forall\lambda$
S>P_S<P $\forall\lambda$
S<P_S>P $\lambda = 7$
S>P_S>P $\lambda <> 7$
5) La majorité de l'ensemble (899 sur 955 clusters) est définie par $k>=8 \text{ ; } \lambda = 7$
où à chaque fois que $S_{x}<P_{x} \text{ & } S_{x}>S_{n}$; x augmente de 1
6) la suite $ S(k) \in{8, 9,10,11,12, 13,....}$ est associée à la suite $ S(tdv) \in{15, 16,17,18,19, 20,....}$ par $\large tdv = k+7$
7) Je peux donc prédire selon 6) que tdv = 1000 pour k = 993
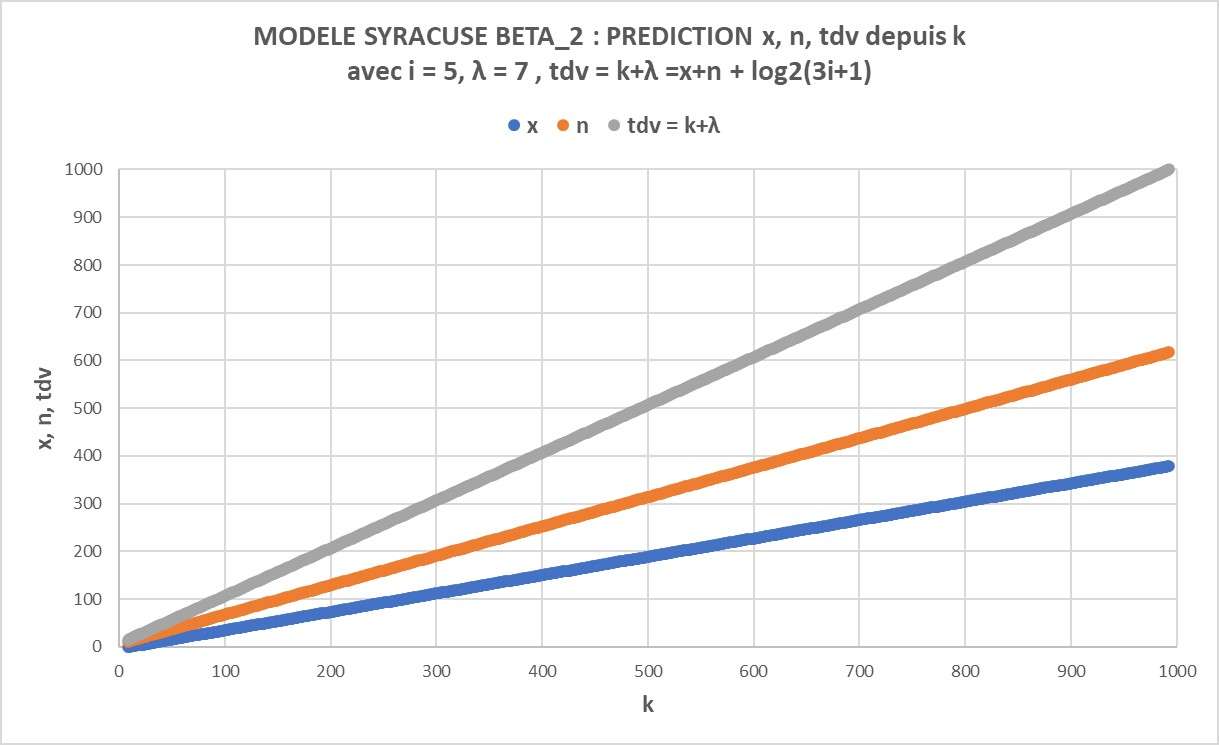
dont je peux estimer x et n en utilisant les paramètres de régression linéaire de la bdd
x = 0,3846*k -3,4097 = 0,3846*993 -3,409 = 379
n = 0,6154*k + 6,4097 = 0,6154*993 + 6,4097 = 617
On remarque que la formule ''classique'' $tdv = x+n+log_2{3i+1}$ fonctionne avec $ i = 5 : tdv = 379+617+log_2{3*5+1} = 1000$
Mais ce cluster 379_617_5_1000 existe-t-il ?
8) Revoyons la formule de Collag3n http://www.les-mathematiques.net/phorum/read.php?43,1993402,1994024#msg-1994024
$tdv=\lceil x\cdot \log_2{6}+\log_2{i'} \rceil $
mais après quelques essais, je vois que cette formule ne permet pas de renvoyer une valeur correcte de i'
Donc je demande à la communauté :
Quelle idée avait vous pour au moins estimer le i' minorant d'un cluster dont le i = 5 ?
https://imagizer.imageshack.com/img924/6482/PQqwJT.jpg
https://imagizer.imageshack.com/img922/8988/m1UGdf.jpg -
Voilà la mise en pratique des qualités prédictives du MODELE SYRACUSE beta_2
1) Une suite k de 8 à 993 génère 986 clusters qui ont tous i = 5 : cela consiste donc à prédire 986 x, n et tdv.
dont voici le graphique
https://imagizer.imageshack.com/img923/1226/6XlcGB.jpg
2) 653 de ces clusters sont hors de ma bdd actuelle
pour les 333 qui en font partie, le résultat est :
38 résultats incorrects 11%
295 résultats corrects 89%
Donc un résultat "plutôt" vrai.
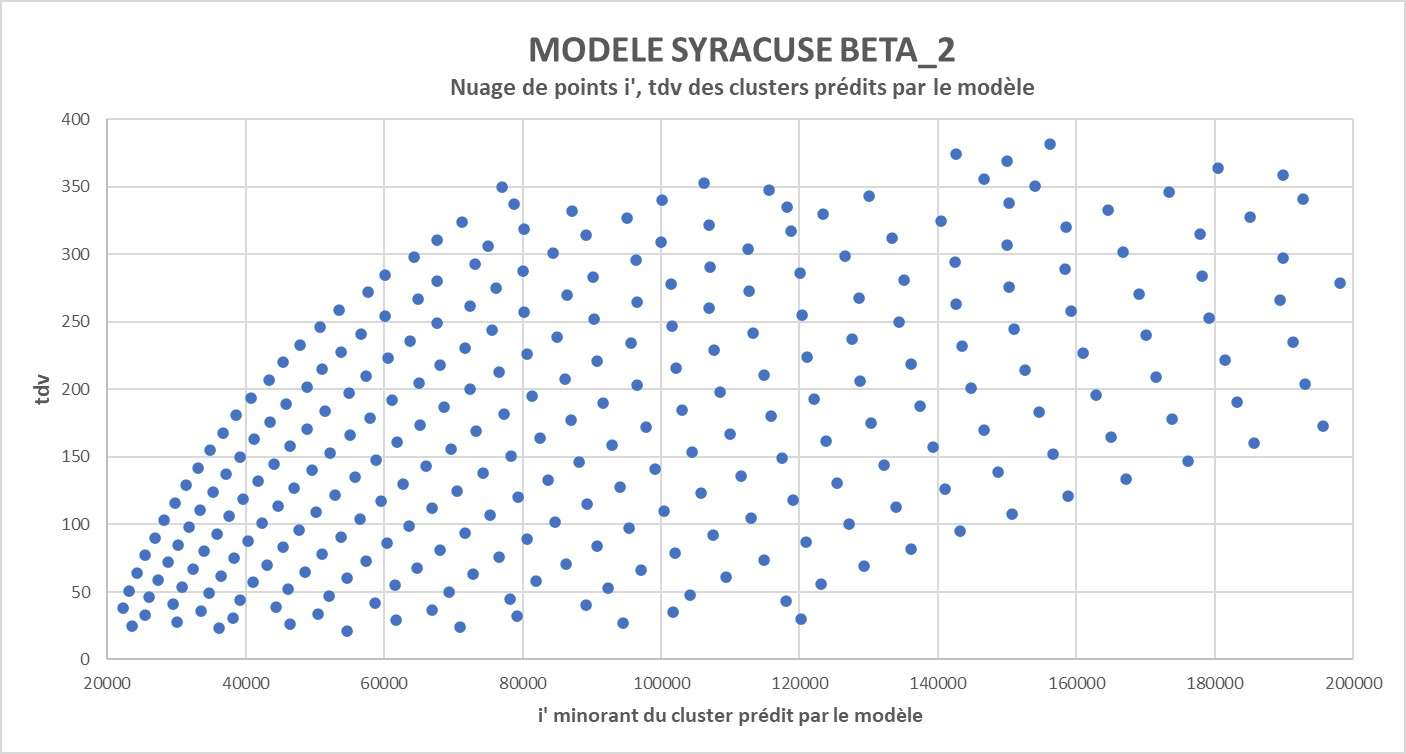
3) Pour les clusters jugés corrects, je peux vérifier dans la bdd à quel i' minorant de cluster ils correspondent.
Ce qui permet d'obtenir ce nouveau graphique
Je tiens à signaler que si vous n’étiez pas convaincus des alignements dans ces nuages de points, là il va falloir vous y faire !
https://imagizer.imageshack.com/img922/7355/phFUdR.jpg
4) Je joins le pdf des résultats du modèle
5) je cherche une formule pour trouver les i' depuis les informations du cluster -
En complément du message http://www.les-mathematiques.net/phorum/read.php?43,2058452,2062626#msg-2062626
Analyse d'une erreur de prédiction détectée pour :
70_125_5_199 pour k = 192
voici les infos dans la bdd proche du tdv 199
i'______________tdv_________x___________n__________i__________x_n_i_tdv"
108 569________198_________70_________124_________5_________70_124_5_198
36 637_________199_________71_________124_________5_________71_124_5_199 prédit 70_125_5_199
72 379_________200_________71_________125_________5_________71_125_5_200
Dans la bdd x a switché sur 71 en gardant n à 124 alors que le modèle prédisait que x reste à 70 mais que n passe à 125
Avec k entre 16 et 284, je trouve 19 erreurs et 250 résultats corrects
les k en erreurs sont :
179, 192, 205, 210, 218, 223, 231, 236, 241, 244, 249, 254, 257, 262, 267, 270, 275, 280, 283
merci de m'indiquer si vous voyez une régularité dans cette suite. -
Bonsoir
en passant à Homeomath pour :
x = 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19
f(x) = 179, 192, 205, 210, 218, 223, 231, 236, 241, 244, 249, 254, 257, 262, 267, 270, 275, 280, 283
j'obtiens ce polynôme de degré 18 :
5552019041287808/231334126720251x^18-23855918139206720000/8357622866791985x^17+21/8124348675053469x^16+248826657258485060000/1575121842900819x^15+21/1352840445696221x^14+23/8356314746385999x^13+23/3973585426572049x^12+23/4971314756043329x^11+49689691735405450/2414605465739613x^10-613954145226059500/3167022679055317x^9+194727956500791560000/2870016177241055x^8-397269871997465900000/5895572683429971x^7+84602760122165460000/5584893429868179x^6-34863599936886206000/714070952846741x^5+11091459810558435000/95204022228915x^4+16883349188177328000/710122550484241x^3+21/6367356606207783x^2-6211539488228515000/6279892436570009x+127868
BERKOUK -
Excellent.
PMF, voilà une piste qui devrait bien alimenter les recherches de PMF Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
Merci Berkouk !
-
Mon cher Lourran
A ce jour le modèle Syracuse peut prédire des clusters x_n_i_tdv à partir d'une simple suite des entiers naturels k.
Je profite donc de ton retour pour te présenter les premiers résultats.
Soit donc une suite k de raison 1 de 16 à 178
On paramètre le modèle avec i = 5, et $\lambda$ = 7
On essaie de prédire des variables x, n, tdv avec une fonction $\large tdv = k+\lambda$
ça donne donc une liste comme ça
k______tdv
16______23
17______24
18______25
19______26
20______27
21______28
....
le x est prédit ainsi :
$ x = \lfloor 0,3846*k -3,4097 \rceil $
et le n :
$ n = \lfloor 0,6154*k +6,4097 \rceil $
Notre petite liste s'est donc agrandie
k_______tdv______x______n_______cluster
16______23______3______16______3_16_5_23
17______24______3______17______3_17_5_24
18______25______4______17______4_17_5_25
19______26______4______18______4_18_5_26
20______27______4______19______4_19_5_27
21______28______5______19______5_19_5_28
22______29______5______20______5_20_5_29
23______30______5______21______5_21_5_30
24______31______6______21______6_21_5_31
25______32______6______22______6_22_5_32
26______33______7______22______7_22_5_33
27______34______7______23______7_23_5_34
28______35______7______24______7_24_5_35
29______36______8______24______8_24_5_36
30______37______8______25______8_25_5_37
31______38______9______25______9_25_5_38
32______39______9______26______9_26_5_39
......
Reste à savoir si cette liste est valide
Là je n'ai pas encore l'outil qui ressort un i ' depuis le cluster mais je peux vérifier dans la bdd
Je cherche en fait si x_n_i (où i est égal à 5) existe et à quel tdv il correspond
cette recherche me montre que les tdv sont bons pour tous les x_n_i avec k de 16 à 178
On valide ainsi à la fois les couples x, n et les tdv prédits.
Pour le i' il faut faire une sommeprod avec le xni, le tdv, le rang de cluster que je met à 1 pour avoir le premier i' du cluster qui va donc faire son choix dans la plage de i'.
Le i' trouvé est un minorant de cluster. Son cluster fait partie des clusters d'une orbite (même tdv) et de i = 5. Le cluster à qui ce i' appartient est celui qui a le plus petit x et le plus grand n
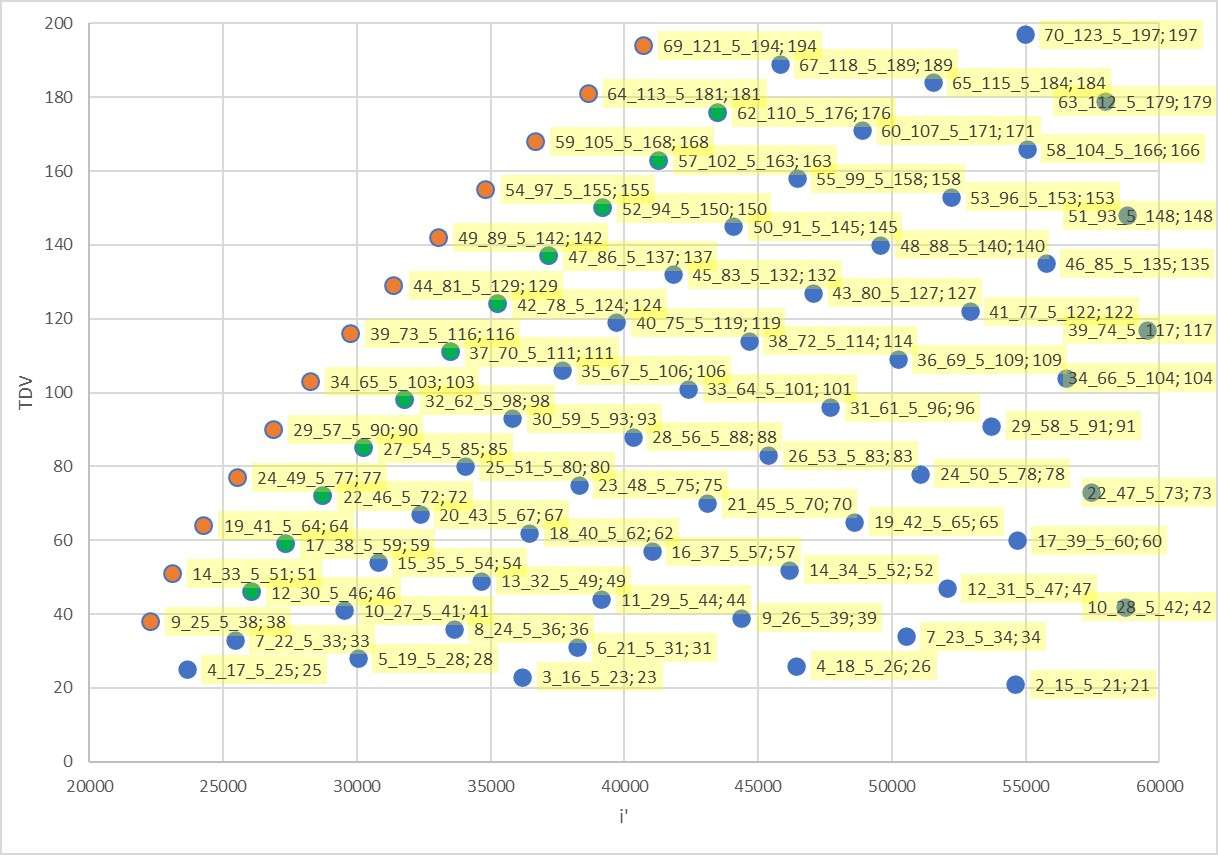
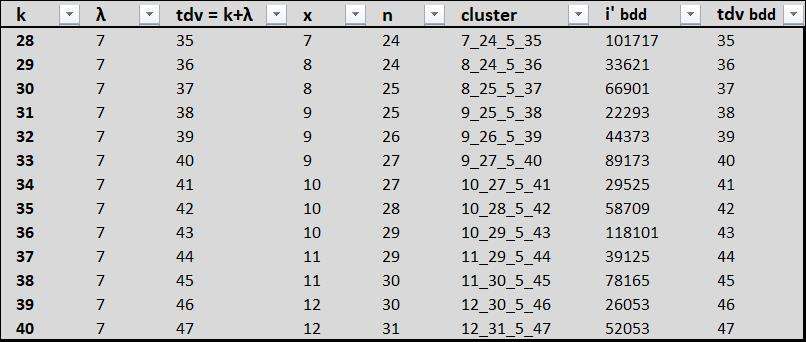
k_______tdv______x______n_______cluster__________i' minorant
16______23______3______16______3_16_5_23______36181
17______24______3______17______3_17_5_24______70997
18______25______4______17______4_17_5_25______23637
19______26______4______18______4_18_5_26______46421
20______27______4______19______4_19_5_27______94549
21______28______5______19______5_19_5_28______30037
22______29______5______20______5_20_5_29______61781
23______30______5______21______5_21_5_30______120149
24______31______6______21______6_21_5_31______38229
25______32______6______22______6_22_5_32______79189
26______33______7______22______7_22_5_33______25429
27______34______7______23______7_23_5_34______50517
28______35______7______24______7_24_5_35______101717
29______36______8______24______8_24_5_36______33621
30______37______8______25______8_25_5_37______66901
31______38______9______25______9_25_5_38______22293
32______39______9______26______9_26_5_39______44373
Voici un zoom du nuage de points de ces i' avec leurs tdv. Les étiquettes de données montrent les x_n_i_tdv
Tout ce petit monde est très bien aligné.
https://imagizer.imageshack.com/img923/9571/2b374t.jpg
Il me semble évident qu'il faut chercher le système de "pavage" qui est aussi efficace qu'une fonction. Un pavage c'est grosso modo comme la déplacement du cavalier sur un jeu d'échecs. On avance de n cases et on se déplace à gauche ou à droite de n cases. La fonction décaler dans les tableur gère très bien ces positionnements.
Ce modèle n'est pas fini mais il montre déjà qu'à partir d'une suite k on prédit des variables x, n, tdv, que l'on va pouvoir lister ainsi les clusters d'une orbite, puis de décrire ce qu'il y a dans les clusters. La chasse aux i' n'est pas des plus faciles, mais il me semblait avoir entendu au début qu'il n'y avait pas de fonctions, et qu'un tdv demandait que l'on calcule la suite avec l'algorithme pour le connaitre....
Mon petit modèle est bien parti pour montrer le contraire. En acceptant quelques ''trous'' dans la liste (mais j'ai sorti la colle) j'ai trouvé pour k de 14 à 375, 295 clusters. Le pdf de cette liste est joint. -
Je ne réagis pas, pour ne pas interférer dans le binôme PMF/Berkouk. Mais je suis tout ça, et je suis impressionné.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin
-
Aujourd'hui nous allons avec le modèle Syracuse visiter la "matrice'' !
Vous vous souvenez, Neo, Morpheus, Trinity et l'agent Smith...
La Matrice est universelle. Elle est omniprésente. Elle est avec nous ici, en ce moment même. Tu la vois chaque fois que tu regardes par la fenêtre ou lorsque tu allumes la télévision. Tu ressens sa présence quand tu pars au travail, quand tu vas à l’église ou quand tu paies tes factures. Elle est le monde qu’on superpose à ton regard pour t’empêcher de voir la vérité.
Et oui, même en maths la matrice est partout, surtout quand on cherche à associer des nombres, à comprendre la structure des suites...
Donc "follow the white rabbit" !
Coup de projecteur sur la vedette du jour, la Matrice :
https://imagizer.imageshack.com/img924/1329/PDysfN.jpg
Cette représentation matricée des clusters correspond à ces données :
https://imagizer.imageshack.com/img922/3664/YjiyvC.jpg
Pas besoin de la "pilule rouge'' pour décoder tout ça. Et ici c'est même le contraire du principe du film que nous allons montrer :
La Matrice est le mode qu’on superpose aux données pour voir la vérité
En effet à moins d'être Rain Man, difficile de voir dans les tableaux de données les associations pourtant si évidentes dès qu'on passe en mode matriciel. Ces données concernent la suite k et ses associations avec les variables de Collatz dont j'ai fait le résumé à l'attention de Lourran hier http://www.les-mathematiques.net/phorum/read.php?43,2058452,2062898#msg-2062898 .
Je disais donc à Lourran "il faut chercher le système de "pavage" qui est aussi efficace qu'une fonction. Un pavage c'est grosso modo comme la déplacement du cavalier sur un jeu d'échecs" Le travail qui a suivi sur le modèle a donc consisté à faire ce "pavage"que l'on peut renommer de manière bien plus efficace " la matrice".
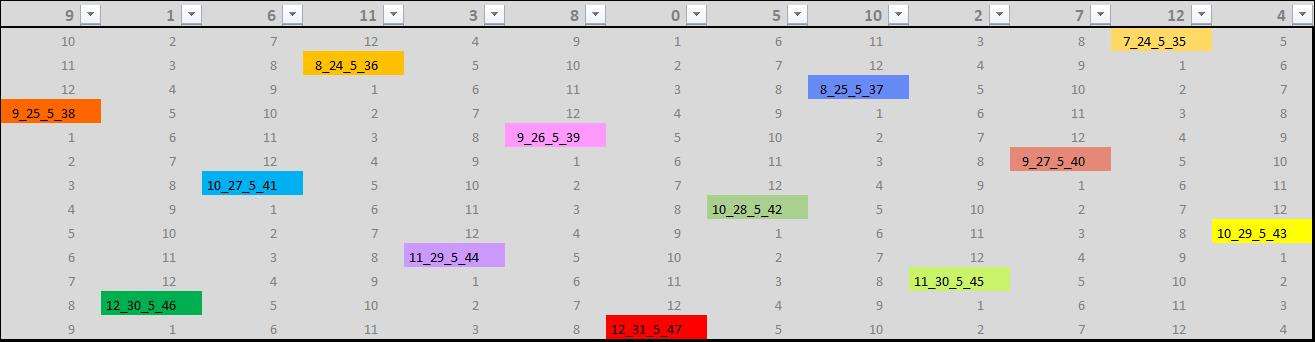
Dans une matrice, une fois que les paramètres sont bien réglés et les règles bien comprises, il suffit de répéter le cycle matriciel avec les mêmes règles pour trouver les nouvelles données. Le modèle est pourvue d'une fonctionnalité qui permet d'afficher dans la matrice, le x, le n, le tdv, le cluster, ou le i'.
Si je descends de quelques cycles (k de 158 à 170) j'obtiens cette fois-ci en affichant les tdv :
https://imagizer.imageshack.com/img924/3800/i8cexO.jpg
Un fois que l'on a réussi à bien caler dans la matrice des variables de Collatz en fonction d'une suite k, on peut commencer à chercher des règles matricielles plutôt que des fonctions. Regardons x par exemple sur 2 cycles matriciels :
https://imagizer.imageshack.com/img922/6481/zJ0GbE.jpg
Il est évident que x = x +5 quand il change de cycle. Voilà donc la règle matricielle pour x !
J'en profite pour faire un petit point technique Excel sur cette matrice. Vous voyez des petits chiffres en gris autour des variables de Collatz.
Les chiffres gris qui sont tout en haut sur la ligne des titres sont les départs de cycle : [1,2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 12, Variable Collatz ]
Si pour la première colonne de la matrice, il y a 9 on va donc avoir dans la matrice [10,11,12, Variable Collatz, 1,2, 3, 4, 5, 6, 7, 8, 9].
Comme vous pouvez le voir ces matrices sont en 13*13 et elles contiennent 13 variables de Collatz au choix : x, n, tdv, cluster, i'
L'objectif prochain du modèle est de trouver toutes les règles x, n, tdv et i'. On aura donc un modèle qui pourra prédire "à l'infini" ces variables x, n, tdv et i' selon ces règles et nous aurons une description complète pour les variables de paramètres communs $ i = 5 \text{_} \lambda = 7$
J'espère avoir été clair dans mes descriptions, et que la lecture de ce fil continue de vous intéresser. Le principe du "journal'' a le défaut de ne pas pouvoir faire le ménage rétro-activement et de prendre beaucoup de temps de rédaction. Mais cela permet de tracer l'évolution du travail, de documenter au fur et à mesure (ce que l'on ne fait pas en développant), et de partager surtout avec les autres. Ce forum est dans une tendance très critique, particulièrement avec les amateurs, mais cela ne me dérange pas. Enfin pas trop.
De l'aide et des encouragements sont aussi appréciables, mais bon on est en période de vacances. C'est déjà pas mal si ce fil est lu de manière régulière. Je joins le pdf avec toutes les matrices en mode i'. Si quelqu'un trouve la règle matricielle de ces i', d'abord bravo parce que c'est la plus dure à trouver et par avance merci. -
Tu es en train de redécouvrir les alignements, comme début mai : latitudes et longitudesTu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin
-
Pas du tout ! du tout, du tout ! Complètement à côté. Fausse pioche totale
1) On est en mode matriciel Lourran et je n'ai fait aucune incursion dans ce mode depuis le tout début de mes fils.
2) Les alignements dont tu parles c'est dans l'ensemble des nuages de points, dans des structures spécifiques aux suites de Collatz
3) La matrice dans mon modèle n'a aucun besoin de savoir si ces données appartiennent à Collatz ou pas. Cela pourrait être des petits pois ou des dromadaires.
4) Je connais bien ce mode matriciel parce que souvent avec les données on fait du ''pavage'' : c'est une manière pour des gens peu matheux comme moi de structurer les données très rapidement. -
Je disais ça parce que tu demandais de l'aide et des encouragements. C'est tout.Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin
-
@lourran : ce que j'ai le plus de difficulté à décoder c'est ta manière d'être avec ce fil de discussion...
Je pense que je vais m'en sortir avec ce modèle et donc décoder à ma sauce les suites de Collatz, sans jamais arriver à te situer
Pour moi-même et les gens qui suivent ce fil, peux-tu prendre une position claire entre ces deux options :
1) "l'amateur PMF ne dit et fait que des bêtises et la seule chose qui m'intéresse est de mettre les rieurs de mon côté "
2) "l'amateur PMF suit une démarche originale qui légitime un fil de discussion, mais je cadre, je corrige, et je développe les concepts mathématiques si besoin en est (ce qui m'empêche pas de rigoler de temps en temps) " -
Je vais te répondre par une autre question :
Tu penses quoi de cette formule :
f(x)=5552019041287808/231334126720251x^18-23855918139206720000/8357622866791985x^17+21/8124348675053469x^16+248826657258485060000/1575121842900819x^15+21/1352840445696221x^14+23/8356314746385999x^13+23/3973585426572049x^12+23/4971314756043329x^11+49689691735405450/2414605465739613x^10-613954145226059500/3167022679055317x^9+194727956500791560000/2870016177241055x^8-397269871997465900000/5895572683429971x^7+84602760122165460000/5584893429868179x^6-34863599936886206000/714070952846741x^5+11091459810558435000/95204022228915x^4+16883349188177328000/710122550484241x^3+21/6367356606207783x^2-6211539488228515000/6279892436570009x+127868Tu me dis, j'oublie. Tu m'enseignes, je me souviens. Tu m'impliques, j'apprends. Benjamin Franklin -
je n'en pense rien. c'est un long polynôme que Berkouk a envoyé par rapport à l'analyse d'une série de données dont j'avais demandé un peu d'aide
J'ai remercié Berkouk mais effectivement ce polynôme ne m'est pas utile
Pour info, en mode matriciel plus aucune formule ne sert à rien. On ne cherche que des règles de déplacement
Mais si pour une série de données, les i' surtout, quelqu'un a une formule, je suis preneur




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Connectez-vous ou Inscrivez-vous pour répondre.
Bonjour!
Catégories
- 163.1K Toutes les catégories
- 7 Collège/Lycée
- 21.9K Algèbre
- 37.1K Analyse
- 6.2K Arithmétique
- 52 Catégories et structures
- 1K Combinatoire et Graphes
- 11 Sciences des données
- 5K Concours et Examens
- 11 CultureMath
- 47 Enseignement à distance
- 2.9K Fondements et Logique
- 10.3K Géométrie
- 62 Géométrie différentielle
- 1.1K Histoire des Mathématiques
- 68 Informatique théorique
- 3.8K LaTeX
- 39K Les-mathématiques
- 3.5K Livres, articles, revues, (...)
- 2.7K Logiciels pour les mathématiques
- 24 Mathématiques et finance
- 312 Mathématiques et Physique
- 4.9K Mathématiques et Société
- 3.3K Pédagogie, enseignement, orientation
- 10K Probabilités, théorie de la mesure
- 772 Shtam
- 4.2K Statistiques
- 3.7K Topologie
- 1.4K Vie du Forum et de ses membres
In this Discussion
Qui est en ligne 34








 +25 Invités
+25 Invités